The Northwind Database is a broadly used and generally understood Database and associated Schema (or Data Dictionary). Thus, it provides a great foundation for demonstrating recent innovations in the realm of Database Management Systems (DBMS), especially in “Graph Databases” vs “RDF Graph Databases” discussions.
This post covers the process and implications of transforming the Northwind Database (here sourced from a collection of CSV documents) into a KnowledgeGraph that manifests as a Semantic Web of Linked Data. Fundamentally, it showcases how hyperlinks as entity identifiers alter the dynamics of entity relationship models by bringing the data to life via the “hypermedium” provided by HTTP-based hyperlinks (or HTTP URIs).
Note: This demonstration is based on attachment of external CSV files, so it requires the Commercial a/k/a Enterprise Edition of Virtuoso. VOS (Virtuoso Open Source Edition) does not support the attachment of remote datasources including external CSV files.
Northwind Database Entity Relationship Model

-
Click HERE to download the Northwind Database (a collection of CSV Documents packed in a Zip Archive). You can also situate yourself in a download folder via your OS command-line interface and issue the following command:
curl -O http://bitnine.net/tutorial/import-northwind-dataset.zip -
From your downloads folder, unzip the Zip Archive using a command like –
unzip import-northwind-dataset.zip– or simply click on the archive file name in the UI of your File Manager, Finder (macOS), or Desktop Explorer (Windows).
-
Move into the
import-northwind-datasetfolder created by the extraction. -
Copy or move all the extracted CSV documents to your Virtuoso installations
vadsub-folder. -
Download the SQL Script containing the commands (
northwind-csv-spasql-demo.sql) by simply clicking or manually downloading – -
Start the Virtuoso iSQL command-line interface, and then execute the following SQL query:
LOAD ./northwind-csv-spasql-demo.sql
What’s Happening Here?
-
Virtuoso will attach (rather than import) all the CSV documents and automatically map each document to a SQL Table (i.e., the content of each document is mapped to an N-Tuple Relation – colloquially referred to as Tables). Note the use of a
file:scheme URI to identify each external CSV document. -
Once the documents are attached, you can verify usability with a sampling of SQL and SPARQL queries:
-- ATTACH CATEGORIES TABLE DROP TABLE csv.northwind.categories; ATTACH_FROM_CSV ( 'csv.northwind.categories', 'file:../vad/categories.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.categories; -- ATTACH CUSTOMERS TABLE DROP TABLE csv.northwind.customers; ATTACH_FROM_CSV ( 'csv.northwind.customers', 'file:../vad/customers.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.customers; -- ATTACH EMPLOYEE TERRITORY TABLE DROP TABLE csv.northwind.employee_territories; ATTACH_FROM_CSV ( 'csv.northwind.employee_territories', 'file:../vad/employee_territories.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.employee_territories; -- ATTACH EMPLOYEES TABLE DROP TABLE csv.northwind.employees; ATTACH_FROM_CSV ( 'csv.northwind.employees', 'file:../vad/employees.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.employees; -- ATTACH ORDER DETAILS TABLE DROP TABLE csv.northwind.orders_details; ATTACH_FROM_CSV ( 'csv.northwind.orders_details', 'file:../vad/orders_details.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.orders_details; -- ATTACH ORDERS TABLE DROP TABLE csv.northwind.orders; ATTACH_FROM_CSV ( 'csv.northwind.orders', 'file:../vad/orders.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.orders; -- ATTACH PRODUCTS TABLE DROP TABLE csv.northwind.products; ATTACH_FROM_CSV ( 'csv.northwind.products', 'file:../vad/products.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.products; -- ATTACH REGIONS TABLE DROP TABLE csv.northwind.regions; ATTACH_FROM_CSV ( 'csv.northwind.regions', 'file:../vad/regions.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.regions; -- ATTACH REGIONS TABLE DROP TABLE csv.northwind.regions; ATTACH_FROM_CSV ( 'csv.northwind.regions', 'file:../vad/regions.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.regions; -- ATTACH SHIPPERS TABLE DROP TABLE csv.northwind.shippers; ATTACH_FROM_CSV ( 'csv.northwind.shippers', 'file:../vad/shippers.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.shippers; -- ATTACH SUPPLIERS TABLE DROP TABLE csv.northwind.suppliers; ATTACH_FROM_CSV ( 'csv.northwind.suppliers', 'file:../vad/suppliers.csv', ',', '\n', null, 1, vector(1) ); SELECT TOP 5 * FROM csv.northwind.suppliers; -- ATTACH TERRITORIES TABLE DROP TABLE csv.northwind.territories; ATTACH_FROM_CSV ( 'csv.northwind.territories', 'file:../vad/territories.csv', ',', '\n', null, 1, vector(1,2) ); SELECT TOP 5 * FROM csv.northwind.territories;
Create & Verify Sample Transformations
-- Generate SPARQL from Order CSV
SPARQL
DEFINE get:soft "replace"
SELECT *
FROM <file://../vad/order_details.csv>
{
?s ?p ?o.
}
LIMIT 100;
-- CREATE RDF VIEW using built-in Sponger Cartridge for mapping CSV to RDF Statement Graphs
DROP TABLE csv.northwind.sparql_order_details ;
CREATE VIEW csv.northwind.sparql_order_details AS
SPARQL
SELECT
?orderID
?productID
?unitPrice
?quantity
?discount
FROM <file://../vad/order_details.csv>
WHERE
{
?s a <file://../vad/order_details.csv#class>;
<file://../vad/order_details.csv#productID> ?orderID;
<file://../vad/order_details.csv#productID> ?productID;
<file://../vad/order_details.csv#unitPrice> ?unitPrice;
<file://../vad/order_details.csv#productID> ?quantity;
<file://../vad/order_details.csv#productID> ?discount.
};
-- Modified Test Query
SELECT TOP 5 Y.orderID
FROM
(
SPARQL
SELECT
?orderID
?productID
?unitPrice
?quantity
?discount
FROM <file://../vad/order_details.csv>
WHERE
{
?s a <file://../vad/order_details.csv#class>;
<file://../vad/order_details.csv#orderID> ?orderID;
<file://../vad/order_details.csv#productID> ?productID;
<file://../vad/order_details.csv#unitPrice> ?unitPrice;
<file://../vad/order_details.csv#quantity> ?quantity;
<file://../vad/order_details.csv#discount> ?discount.
}
LIMIT 5
)
AS X
INNER JOIN "csv"."Northwind"."Orders" Y
ON X.orderID = Y.orderID;
Mapping Tables to RDF Graphs, and Storing those Mappings
At this juncture, based on script above, Virtuoso would have only generated Virtual 3-Tuple Relations (Triples) associated with a Named Graph (Data Source Identifier/Name) associated with its Virtual RDF Storage, rather than Physical 3-Tuple Relations (Triples) associated with a Named Graph associated with its Physical RDF Storage.
Virtual Storage can be identified by an IRI using DEFINE input:storage {storage-IRI}, if the default storage isn’t desired.
Physical Storage is identified by the IRI: <virtrdf:>.
Combined Virtual and Physical Storage is identified by the IRI: <virtrdf:DefaultQuadMap>. This is the default mapping, which is used when the built-in wizards map Tables to RDF Graphs.
To generate Physical Triples, the following would need to be executed:
SPARQL
SELECT COUNT(*)
FROM <http://demo.openlinksw.com/csv_northwind#>
WHERE { ?s ?p ?o } ;
RDF_VIEW_SYNC_TO_PHYSICAL ( 'http://demo.openlinksw.com/csv_northwind#',
1,
'urn:demo:csv_northwind:data'
);
SPARQL
SELECT COUNT(*)
FROM <urn:demo:csv_northwind:data>
WHERE { ?s ?p ?o } ;
What’s the difference between Virtual and Physical Triples?
Virtual Triples are directly translated to SQL “on the fly” when queries are executed. They have a fundamental shortcoming in the performance of queries that operate on instances of classes via rdf:type (a/k/a isA) relations, because UNIONs need to be constructed across the Tables associated with instances of classes when the object of rdf:type relations takes the form of a variable.
Physical Triples don’t have any performance issues with variables that identify the objects of an rdf:type relation, but they do introduce a change-sensitivity challenge: what happens when data is altered in the original CSV document or some other relevant Table (such as one referenced through an ODBC connection)?
Change-sensitivity is addressed via the following options:
-
A
TRIGGERmay be set on the source SQL Table. For example, in this exercise we have a native Virtuoso Table (where triggers are supported) generated from a CSV document using a file system reference, courtesy offile:scheme URI. -
A
STORED PROCEDUREcan be used to apply a delta-calculation to the source en route to adding or deleting triples from a Named Graph associated with a Physical RDF Store.
RDF Views
Having successfully verified the binding between the filesystem-hosted CSV documents and Relations in Virtuoso, you can proceed to generate a highly navigable KnowledgeGraph based on RDF Views that manifests as a Semantic Web of Linked Data.
You have the following options for generating these powerful views:
-
Virtuoso’s built-in Transformation Middleware (“Sponger”) – which generates RDF Statement Graphs from CSV documents “on the fly” (as with the
file:reference and usage in the examples above) -
Virtuoso’s built-in RDF Views Wizard – which automatically generates a Knowledge Graph that manifests as a Semantic Web of Linked Data
-
R2RML Scripts – which are comprised of a collection of RDF-Turtle statements that describe the desired mappings from Relational Tables to RDF Statement Graphs. An R2RML Script for the CSV edition of the Northwind Database used in this post may be found here:
- Virtuoso Quad Maps – which are comprised of a collection of SPASQL (fusion of SQL Procedures and SPARQL) statements that map out your desired mappings from Relational Tables to RDF Statement Graphs
Live Demo Examples
Here are live examples from a Northwind Knowledge Graph generated using the RDF Views defined above. It consists of various entities, denoted by hyperlinks (specifically, HTTP URIs), which resolve to entity description pages.
-
http://demo.openlinksw.com/schemas/csv_northwind/ – identifies Ontology that describes Entities, Entity Types, and Entity Relationship Types
-
http://demo.openlinksw.com/csv_northwind/categories/categoryid/1#this – Identifies a specific Category Entity derived from the Category Table mapping
-
http://demo.openlinksw.com/csv_northwind/customers/customerid/ALFKI#this – Identifies a specific Customer Entity derived from the Customer Table mapping
-
http://demo.openlinksw.com/csv_northwind/employees/employeeid/1#this – Identifies a specific Employee Entity derived from the Employee Table mapping
-
http://demo.openlinksw.com/csv_northwind/orders/orderid/10248#this – Identifies a specific Order Entity derived from the Order Table mapping
-
http://demo.openlinksw.com/csv_northwind/products/productid/1#this – Identifies a specific Product Entity derived from the Product Table mapping
-
http://demo.openlinksw.com/csv_northwind/regions/regionid/1#this – Identifies a specific Region Entity derived from the Region Table mapping
-
http://demo.openlinksw.com/csv_northwind/shippers/shipperid/1#this – Identifies a specific Shipper Entity derived from the Shipper Table mapping
Conclusion
By collectively standardizing on the user of hyperlinks (specifically, HTTP URIs) to identify documents, the world built a global Document Network via the Internet commonly known as the World Wide Web (a/k/a “Web”).
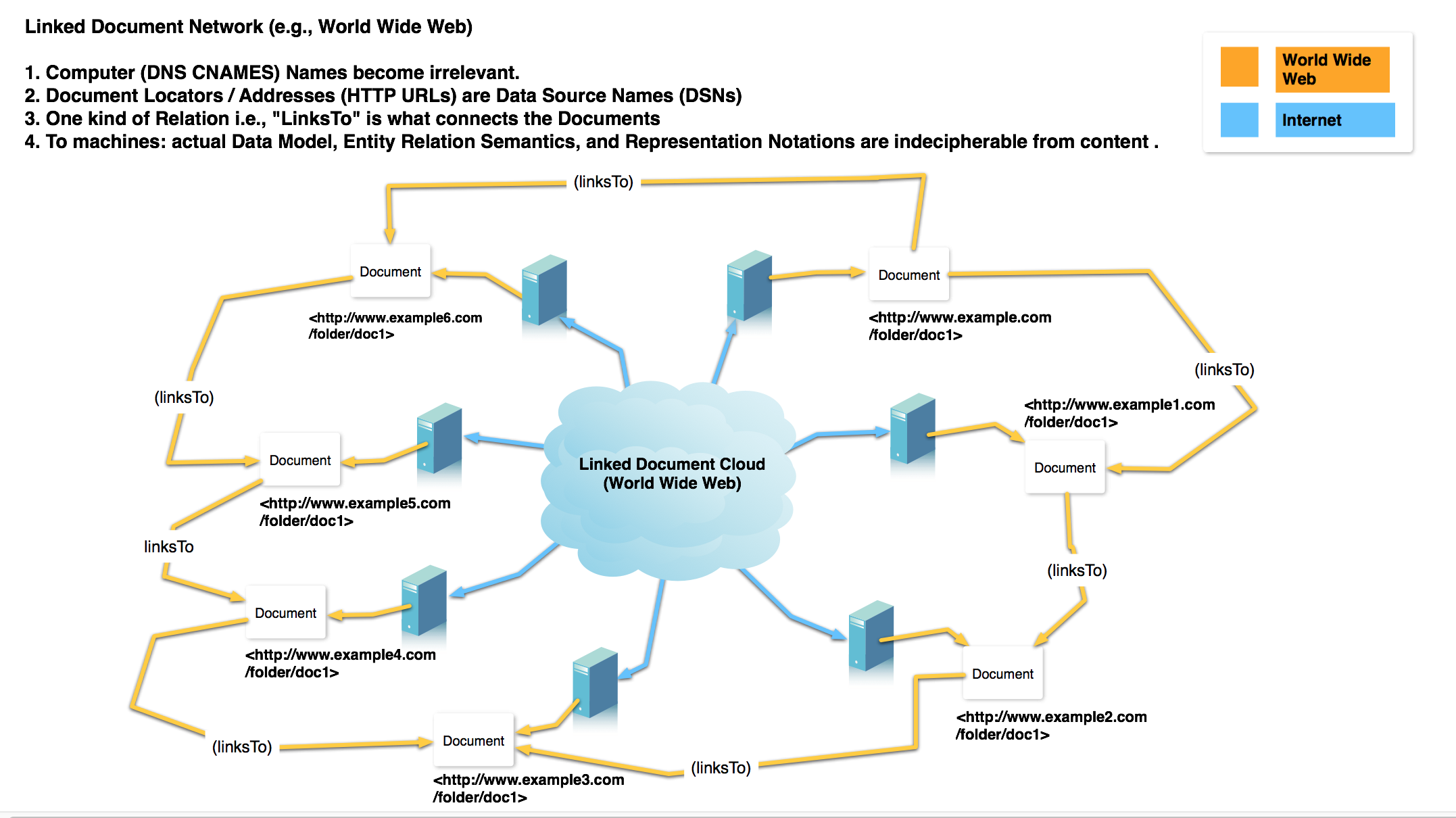
Extending the same approach for identifying documents to the more fine-grained act of structured data representation, based on the Entity Relationship Model, results in a Web of Data (a/k/a “Linked Data”).
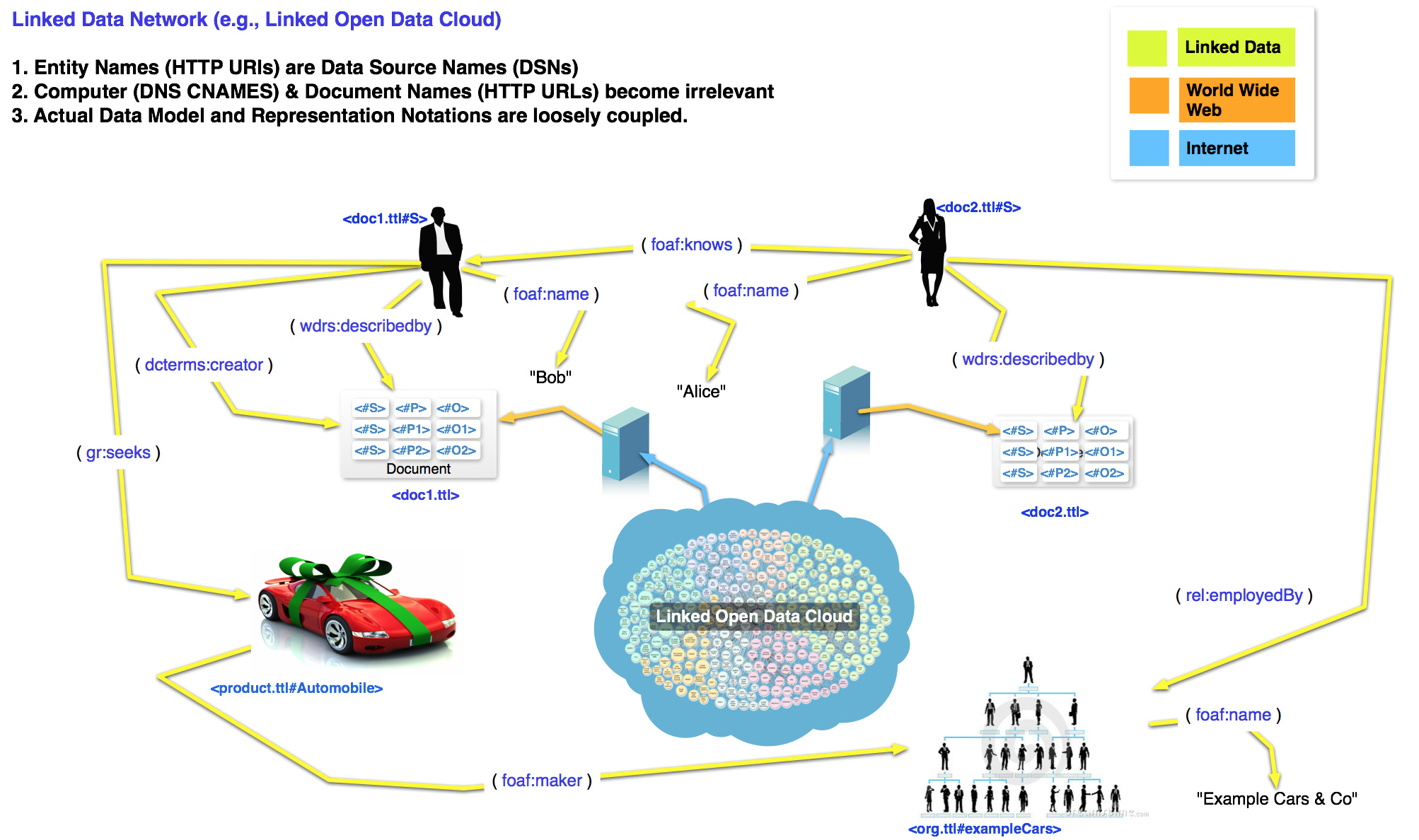
Finally, if you describe the Relationship Types (a/k/a Relations) to cover things like equivalence, inversion, transitivity, sub-classing, symmetry etc., this new web-like Entity Relationship Model becomes a Knowledgebase (or KnowledgeGraph) that manifests as a Semantic Web of Linked Data.
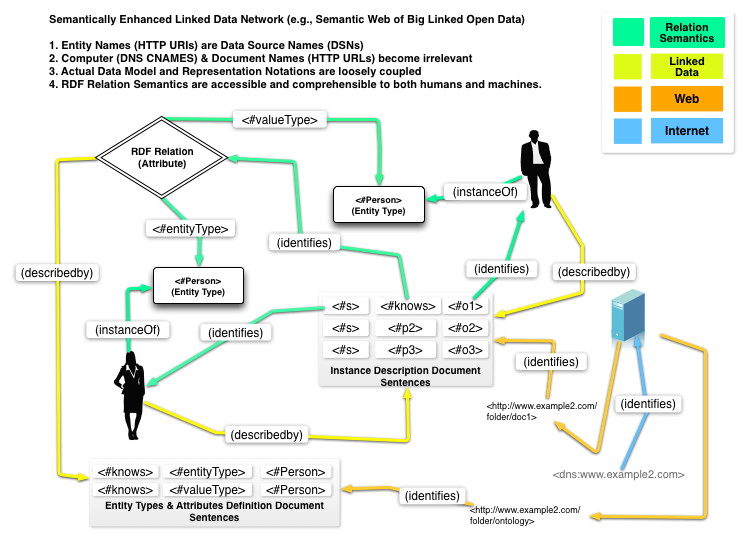
The implications of this powerful innovation on data access, integration, and management are profound, and dwarf everything unleashed by the Web as currently understood and experienced.
In Virtuoso, we have developed an innovative platform that brings all of this power to bear without undue complexity, confusion, or cost. Simply install Virtuoso, and let it guide you through the process of making current and future projects associated with the following themes ultra-successful:
- Digital Transformation
- Market Leadership Discipline Optimization
- Data Monetization – adding new business model dimensions driven by your data without compromising privacy or security
Links
- R2RML Script
- SQL Script including Virtuoso Quad Maps and URL-Rewrite Rules for Linked Data Deployment
- Northwind Ontology generated from the CSV edition of Northwind Database
Related
- Virtuoso SPASQL Script – Attaching Northwind Database (in CSV document collection form) to a Virtuoso instance
- Importing CSV Data Into Neo4j – Import, Query, and Modify Graph Data using Northwind Database (in CSV form) from Neo4j
- AgensGraph Tutorial – Import, Query, and Modify Graph Data using Northwind Database (in CSV form)
- The classic Northwind database converted to the NoSQL world
- Comma Separated Values
- Entity Relationship Model
- Entity-Attribute-Value Model
- Relational Model
- Harmonizing Disparate RDBMS Data using Virtuoso’s built-in Reasoning and Inference functionality
- Tabulated DBMS Genre Comparison