There are many terms that have arisen over the years covering what’s referred to today as Data Virtualization. For instance, Polybase is a new term pushed by Microsoft for this concept when deployed via an DBMS. Likewise, we’ve used the phrase Virtual DBMS for the same thing in the past.
Irrespective of terminology, this post will provide a simple introduction to the concept via a CSV document attached to Virtuoso.
What is Data Virtualization?
Harmonized access to data across disparate data sources. In regards to a conventional SQL-compliant RDBMS this would imply a single point of access for a federation of Tables managed by a variety of DBMS instances which may or may not be of the same brand i.e., a single connection to a Virtual DBMS or Polybase provides operational access to Tables managed by Oracle, SQL Server, MySQL, PostgreSQL, Sybase, DB2, Informix, Ingres, Progress (Open Edge), and other ODBC- or JDBC-accessible DBMS instances.
When should I use Data Virtualization?
Whenever you need a holistic view of data that can only be obtained by fusing data across a variety of data sources. This is typically the case across all enterprises due to the nature of applications that aren’t modeled for data interoperability and integration.
What are the Benefits?
- A common language for data manipulation operations. A modern Data Virtualization platform will include an ability to harmonize operations across SQL-dialects implemented by various DBMS platforms
- Enhanced data utility without data duplication
- Smarter Data Security
Does this replace Extract Transform Load (ETL) jobs?
It depends on the change-sensitivity requirements of the solution you are implementing.
Data Virtualization is more powerful for situations where change-sensitivity is moderate to high.
Isn’t this the same functionality offered by Microsoft SQL Server Linked Servers?
Despite enabling query access to external data from SQL Server there are some fundamental differences:
-
A Linked Server is driven by a Data Source definition at the server level whereas a Virtual DBMS (e.g., Virtuoso) leverage external DBMS metadata that enable a deeper and more sophisticated interaction with an external DBMS (e.g., handling of SQL-dialect differences, location-aware aggregate handling, scrollable cursor harmonization).
-
Linked Server operations are single-threaded whereas Virtuoso operations are fully multi-threaded
-
Virtuoso leverages platform agnostic ODBC and ODBC-JDBC Bridging for external DBMS access rather than platform-specific OLE DB.
Attaching Tables to Virtuoso
This is achieved by issuing SQL-commands via the Virtuoso iSQL command-line interface or the HTML-based Admin UI (a/k/a Conductor).
iSQL Command Line Example
This example assumes the existence of CSV files containing data required for generating Tables based on the Northwind Database Schema. The CSV files are situated in an adjacent folder to the one from which iSQL is being invoked (hence: the “…/vad/” component of the file: scheme URI).
DROP TABLE csv.northwind.suppliers;
ATTACH_FROM_CSV ( 'csv.northwind.suppliers',
'file:../vad/suppliers.csv',
',',
'\n',
null,
1,
vector(1)
);
-- Verify Table Creation
SELECT TOP 5 * FROM csv.northwind.suppliers;
-- ATTACH TERRITORIES TABLE
DROP TABLE csv.northwind.territories;
ATTACH_FROM_CSV ( 'csv.northwind.territories',
'file:../vad/territories.csv',
',',
'\n',
null,
1,
vector(1,2)
);
-- Verify Table Creation
SELECT TOP 5 * FROM csv.northwind.territories;
Automatic Generation of RDF Views that provide an additional Conceptual Layer that leverages Linked Data principles
-- Generate SPARQL from Order CSV
SPARQL
DEFINE get:soft "replace"
SELECT *
FROM <file://../vad/order_details.csv>
{
?s ?p ?o.
}
LIMIT 100;
-- CREATE RDF VIEW using built-in Sponger Cartridge for mapping CSV to RDF Statement Graphs
DROP TABLE csv.northwind.sparql_order_details ;
CREATE VIEW csv.northwind.sparql_order_details AS
SPARQL
SELECT
?orderID
?productID
?unitPrice
?quantity
?discount
FROM <file://../vad/order_details.csv>
Query Data Across External Data Sources
At this juncture we have Tables attached to Virtuoso from the CSV-rendition of the Northwind Database Schema. In addition, we also have tables attached from MySQL 5 plus local renditions of the same Tables via Virtuoso’s own Demo Database Schema.
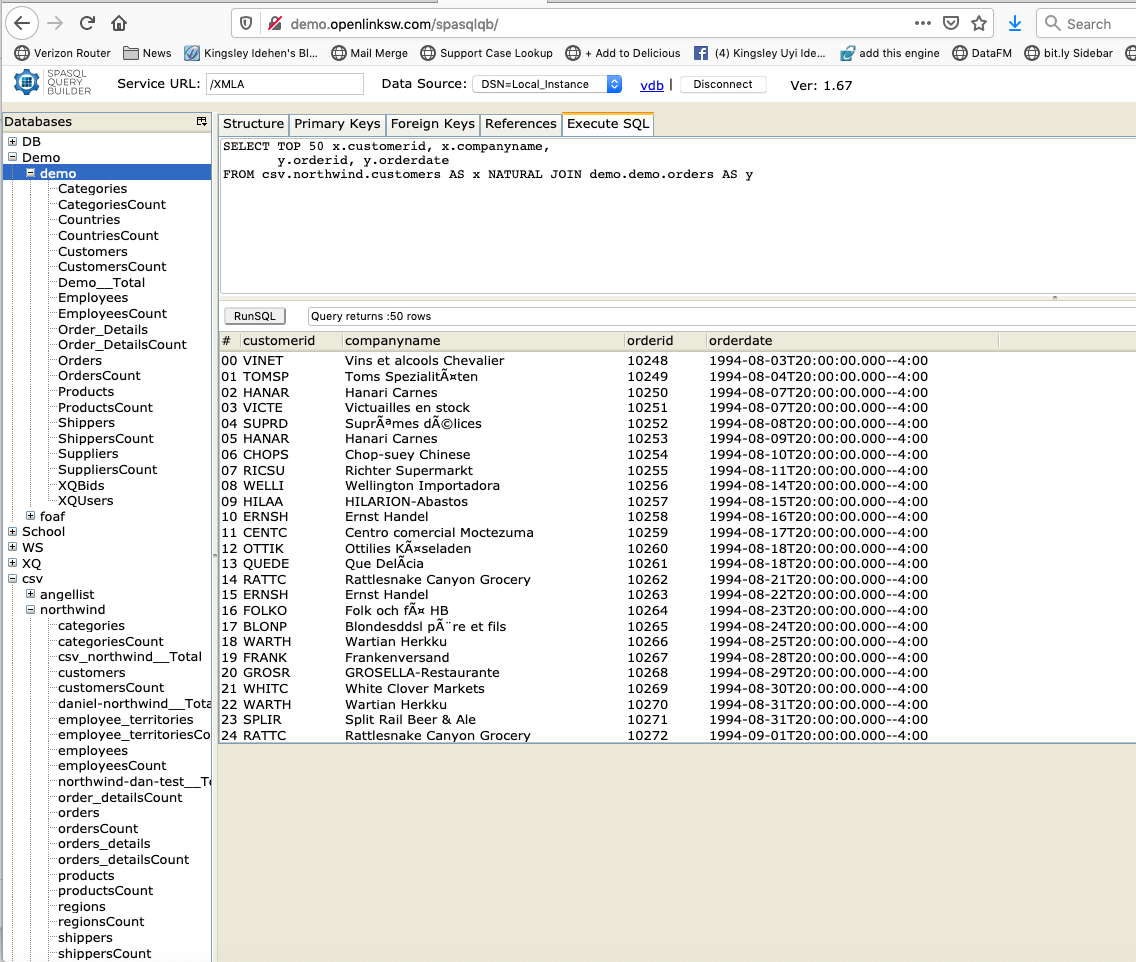
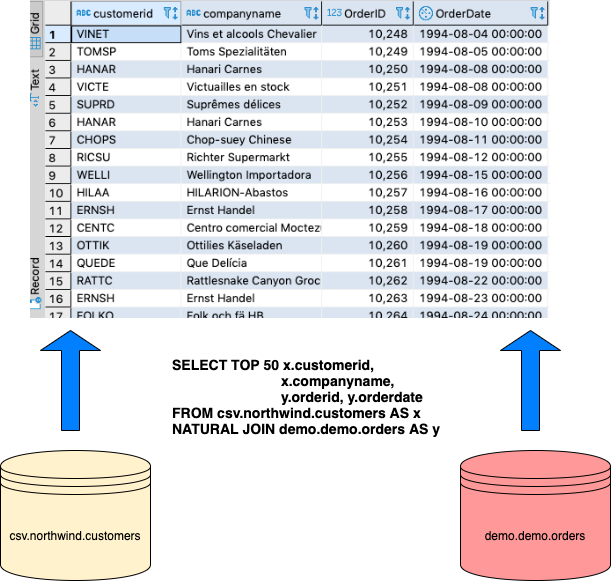
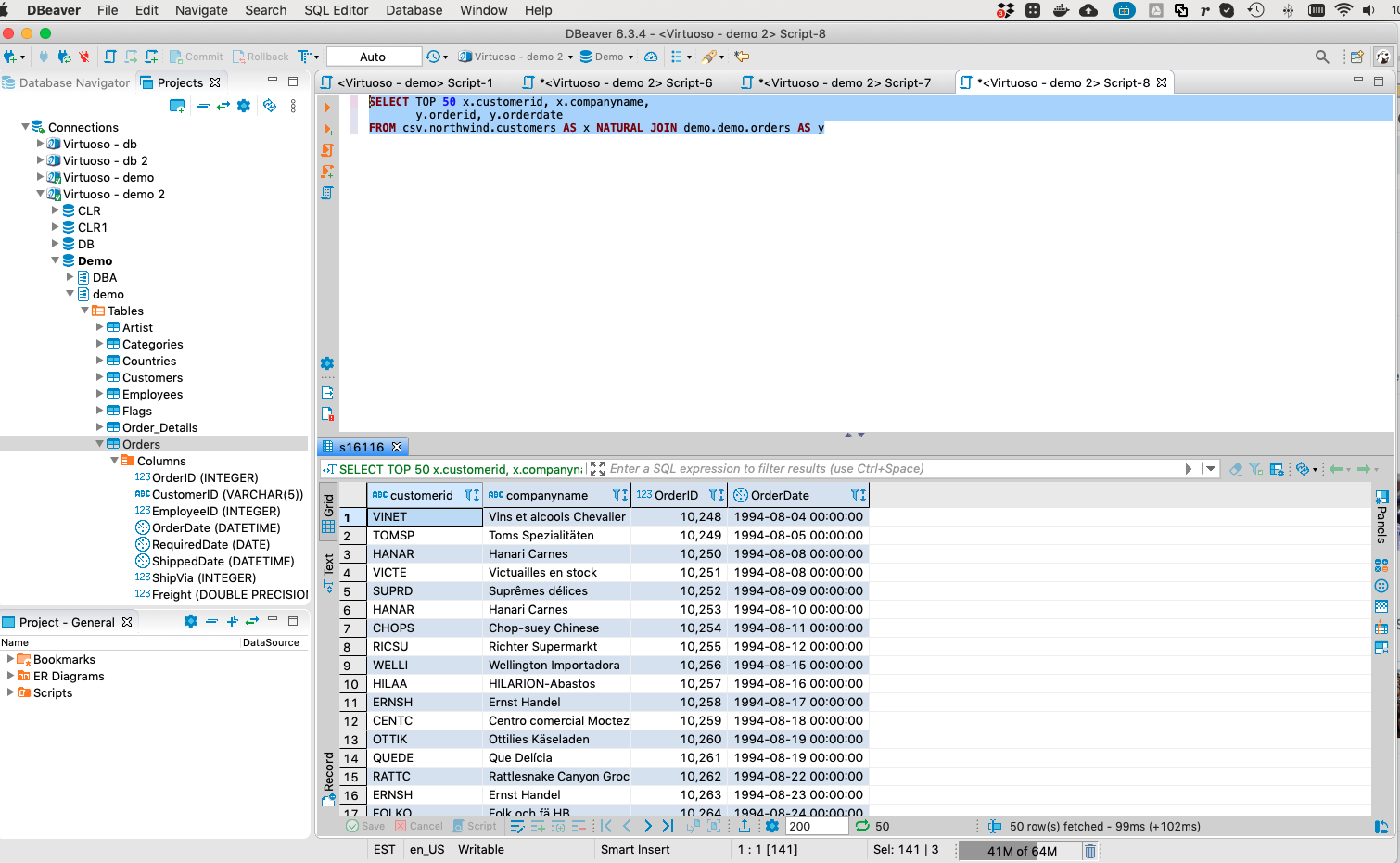
SELECT TOP 50 x.customerid, x.companyname,
y.orderid, y.orderdate
FROM csv.northwind.customers AS x NATURAL JOIN demo.demo.orders AS y
Courtesy of our HTML5-based Query-By-Example Tool, we can also produce a live example of the query demonstrated above.
To make this possible, we need to create a user account (in this case “vdb”) that has restricted DBMS privileges e.g., SELECT access is only granted on the csv.northwind.customers (attached from a CSV file) and demo.demo.orders (from Virtuoso’s Demo Schema) tables.
GRANT SELECT ON “csv”.“northwind”.“customers” TO “vdb” ;
GRANT SELECT ON “demo”.“demo”.“orders” to “vdb” ;
Here is a Live Link to a SQL query results page using our HTML5-based Query-By-Example tool.
Provide username and password “vdb” when challenged for authentication credentials.