In this post I demonstrate how to exploit Knowledge Graphs embedded in HTML documents using a selection of productivity tools from our product portfolio. Note, an increasing number of HTML documents published to the Web now include enhance metadata in the form of RDF-based structured data islands constructed using terms from the Schema.org vocabulary [1].
My tools of choice are as follows:
- OpenLink Structured Data Sniffer (OSDS) – for Chrome and other Chromium-based Browsers that support the Web Extensions open standard
- OpenLink Structured Data Sniffer (OSDS) – for Firefox
- OpenLink Structured Data Bot (OSDB)
- OpenLink SPASQL Query Builder (OSQB)
Situation Analysis
While browsing my Twitter feed, I stumbled upon an article about AMC Cinemas and its recent stock volatility.
Using a variety of OpenLink Tools, I want to progressively create and exploit a Knowledge Graph hosted by our URIBurner service with content originating from HTML pages published by MarketBeat.
Why is this important?
Whether as an individual or as part of a team, your competitive advantage is inextricably linked to your access to information and knowledge, which are created by the acts of creating data and putting that and other data in context.
How do I pull this off?
Using the OpenLink Structured Data Sniffer (OSDS) Browser Extension
If you have OSDS installed, you can simply perform the following steps while the page in question is in your browser’s view:
-
Click on the OSDS icon (
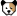 ) in your browser’s toolbar. This serves as a shortcut for constructing a SPARQL Query embedded in a URIBurner Service URL, which returns a description of this HTML document.
) in your browser’s toolbar. This serves as a shortcut for constructing a SPARQL Query embedded in a URIBurner Service URL, which returns a description of this HTML document. -
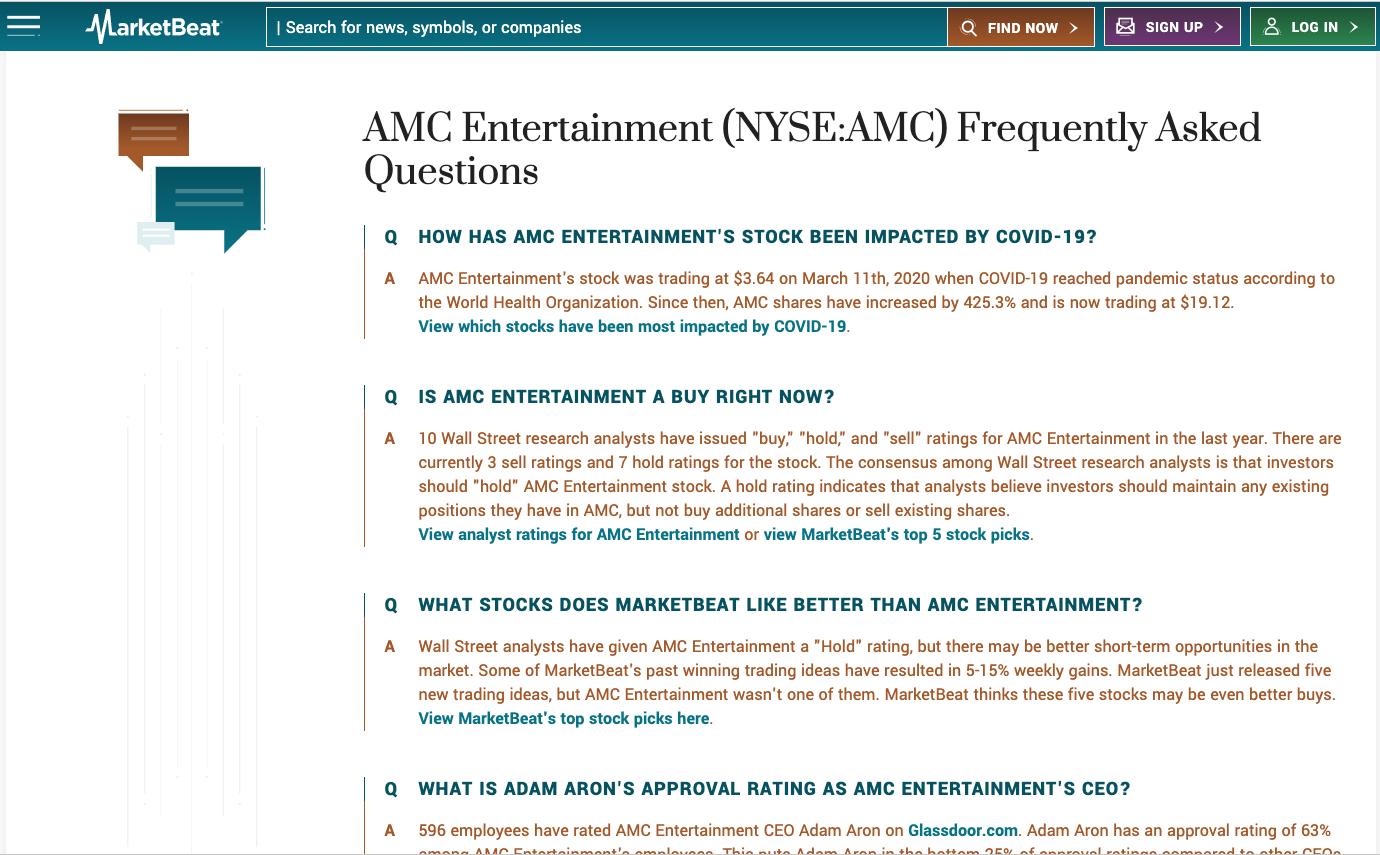
The HTML document description returned by the URIBurner Service includes a SPARQL Query Results page, which in turn includes Hyperlinks that function as a conduit to a progressively generated segment of a larger Knowledge Graph, which also includes new facts contributed through loosely-coupled Named Entity Recognition (NER) and Natural Language Processing (NLP) services.
-
Click again on the OSDS icon (
) in your browser’s toolbar, and then on the Super Links icon ( ) in the OSDS sub-window. This will match key entities mentioned in and/or related to the document text to entities from across the LOD Cloud Knowledge Graph.
) in the OSDS sub-window. This will match key entities mentioned in and/or related to the document text to entities from across the LOD Cloud Knowledge Graph. -
Click on a highlighted item of interest – which will lead to an Entity Description Page, presented as an Entity-Attribute-Value property sheet.
Screenshot Sequence
-
Market Beat Page
-
OSDS Extension, activated on Market Beat Page
-
At the end of this process you will have a hyperlink that functions as a data source name for interacting with the progressively generated knowledge graph via SPARQL. In addition, you will have a data source name that enables interaction with the OpenLink Smart Data Bot (OSDB).
Using the OpenLink Structured Data Bot (OSDB)
-
Take your web browser to https://osdb.openlinksw.com.
-
Click on the “Manage Services” link – note, this is a privileged service, so only registered and permitted members can perform this action.
-
Provide the URIBurner Generated URL — i.e., the “data source name” from above — and your preferred Text Label as values for the respective input fields presented.
-
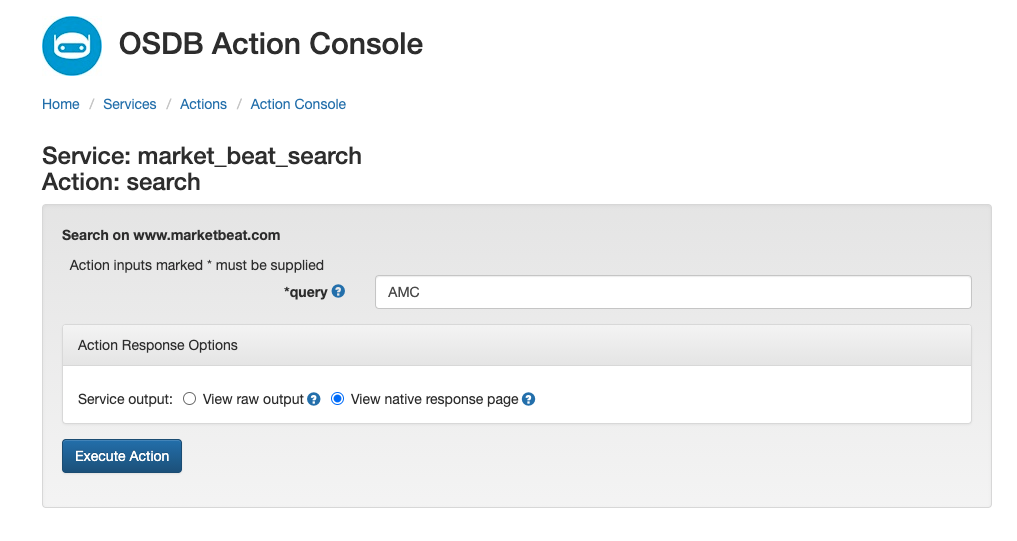
Click on the newly registered service – in this case, a “Search Action”.
-
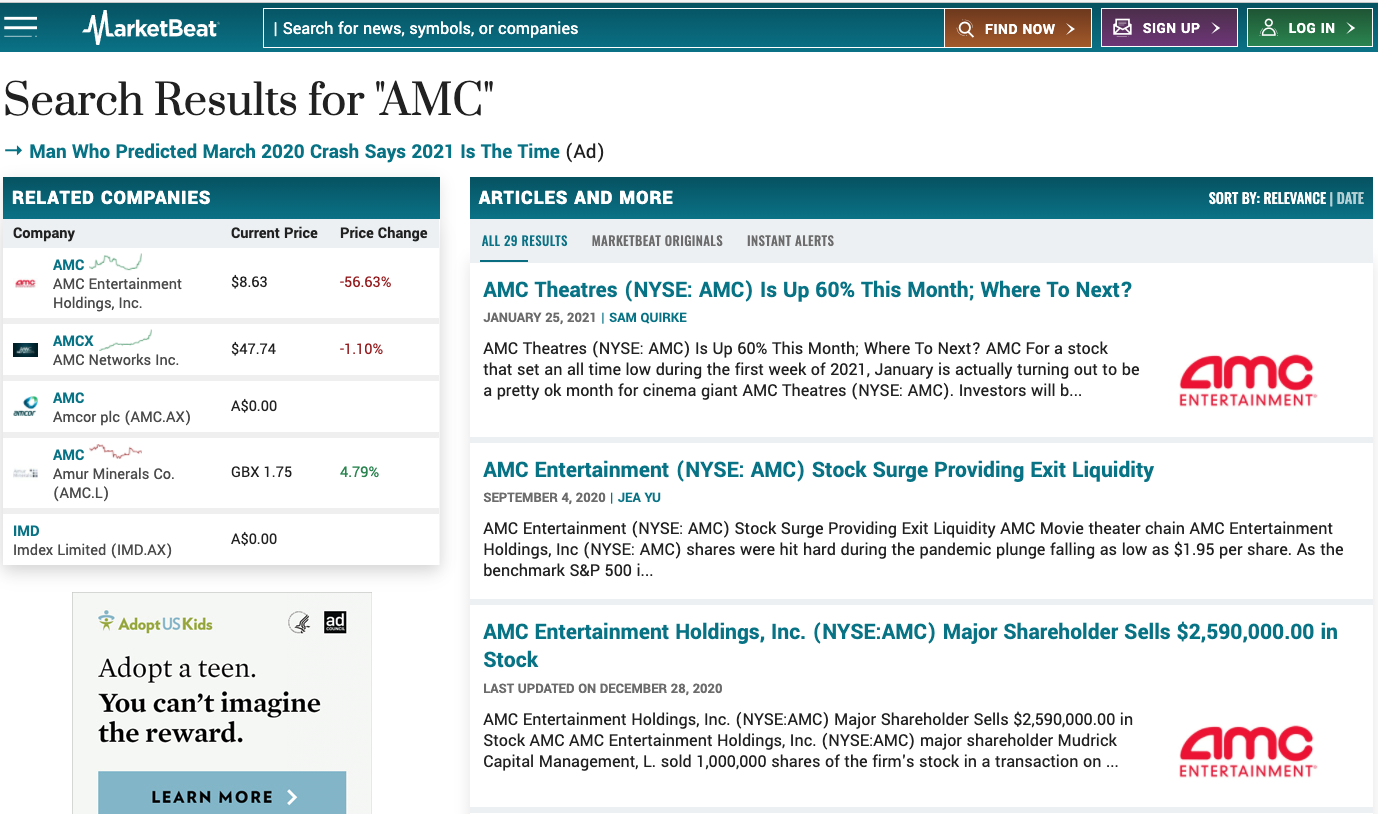
Click on the “Build Console” link and enter a keyword, e.g., “AMC”.
OSDB Screenshots
-
Generated Search Console
-
Search Results Page
Using the OpenLink SPASQL Query Builder (OSQB)
-
Go to the SPARQL Query Service Endpoint associated with your Virtuoso instance.
-
Put the URL of the Market Beat document (i.e., https://www.marketbeat.com/stocks/NYSE/AMC/) into the “Default Named Graph” input field to set the Data Source Name for your query. This has the added benefit of including the target Data Source Name as part of the SPARQL Wire-Protocol URL that resolves to the actual query solution.
-
Type in your Query Text.
-
Execute your Query by clicking on the “ Run ” button.
Note 1: You will receive an authentication challenge (unless you’re in a browser session which has already authenticated with the URIBurner instance), because using Named Graphs derived from external Document Locations is a privileged operation, as designated by the Attribute-Based Access Control applied to the URIBurner Instance.
Basic Query Example
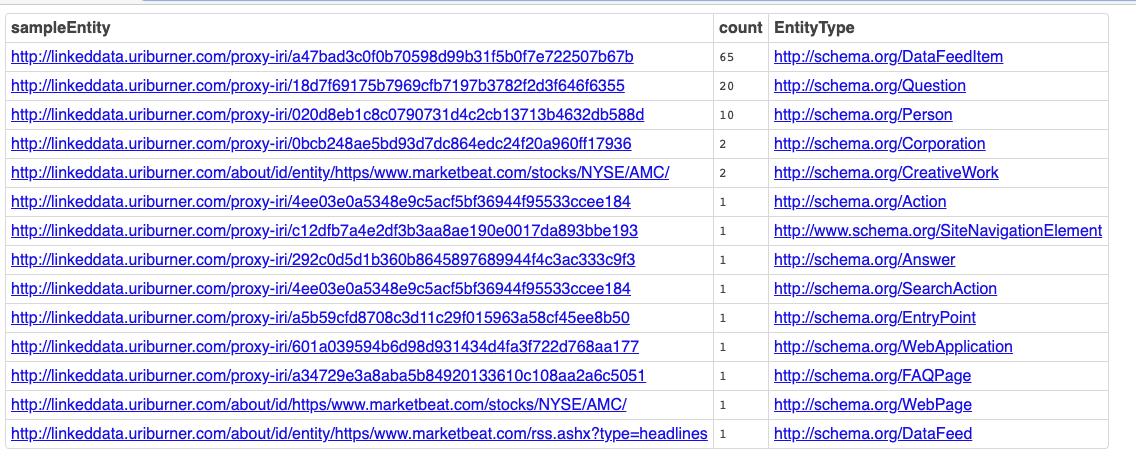
SELECT ( SAMPLE ( ?s ) AS ?sampleEntity )
( COUNT ( * ) AS ?count )
( ?o as ?EntityType )
WHERE {
?s a ?o .
FILTER ( ISIRI ( ?s ) )
FILTER ( CONTAINS ( STR ( ?o ) , "schema." ) )
}
GROUP BY ?o
ORDER BY DESC (?count)
Here’s the Query Results Page.
Results Page Screenshot
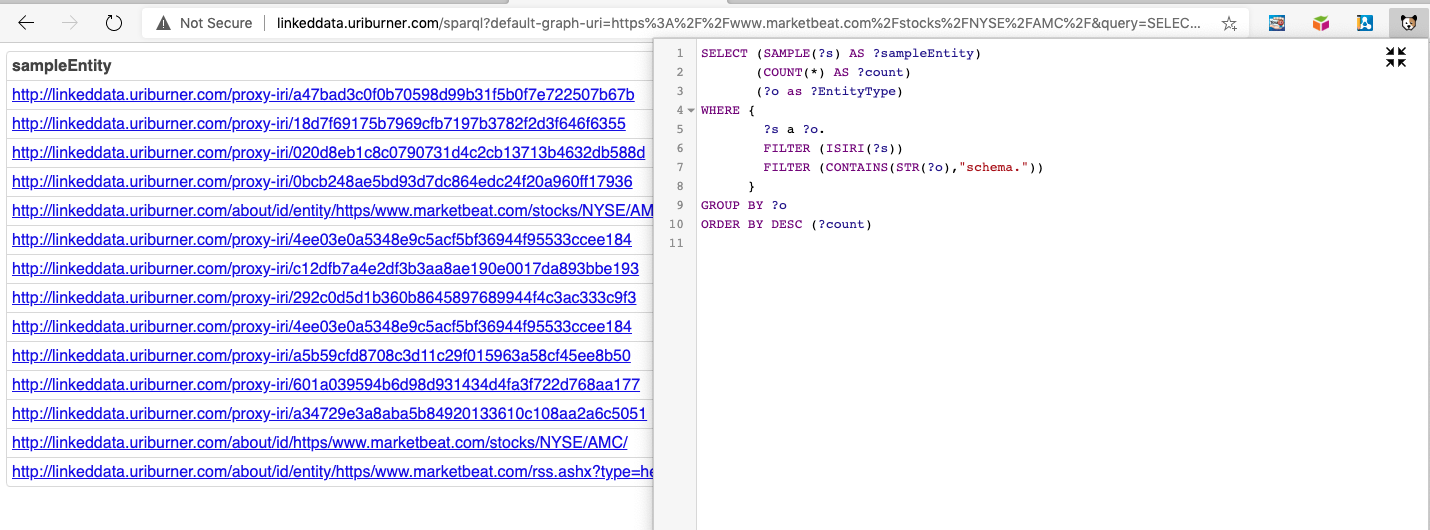
If I want to incorporate the Data Source Name (what I set as the Default Named Graph for the query above) within into the SPARQL Query Text, the query would be as follows:
DEFINE get:soft "soft"
SELECT ( SAMPLE ( ?s ) AS ?EntityID )
( COUNT ( * ) AS ?count )
( ?o AS ?EntityTypeID )
FROM <https://www.marketbeat.com/stocks/NYSE/AMC/>
WHERE { ?s a ?o }
GROUP BY ?o
ORDER BY DESC 2
LIMIT 50
Here’s the Query Results Page.
Results Page Screenshot, including Query Definition via OSDS
Using the SPASQL Query Builder
This use case demonstrates the use of SQL and SPARQL combined (via Federated Query Functionality) to operate on the same data originating from a Marketbeat HTML document (or Web Page). Here are the steps to follow:
-
Go to the publicly accessible SPASQL Query Builder at http://demo.openlinksw.com/spasqlqb/.
-
Authenticate using
vdbfor both username and password -
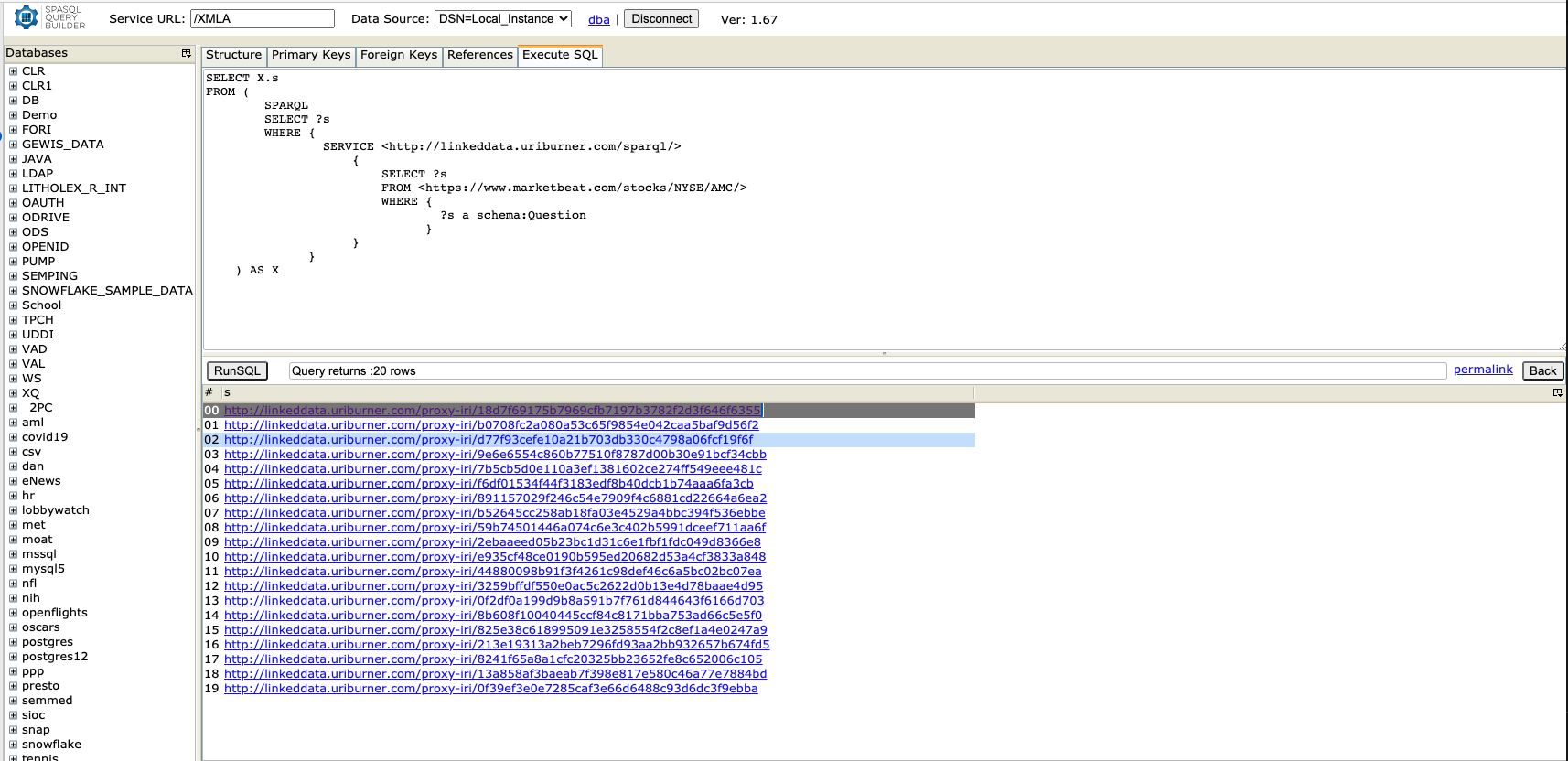
Type in (or copy and paste) the following query:
SELECT X.s FROM ( SPARQL SELECT ?s WHERE { SERVICE <http://linkeddata.uriburner.com/sparql/> { SELECT ?s FROM <https://www.marketbeat.com/stocks/NYSE/AMC/> WHERE { ?s a schema:Question } } } ) AS XSPASQL Query Builder Screenshot
-
Here’s the Query Results Page.
What’s Happening Here?
Virtuoso Sponger Middleware (“Sponger”)
The Sponger performed the following tasks, using the URL of the HTML document in your browser as a Data Source Name:
-
Extracted content (RDF and non-RDF) from the document
-
Transformed non-RDF content to RDF (i.e., a collection of Entity Relationship Types)
-
Applied Entity Recognition and Natural Language Processing to the generated RDF
-
Loaded the transformed and enriched RDF data into Virtuoso
As a result, the FAQ and other information embedded in the HTML document is progressively added to a larger Knowledge Graph maintained by our publicly accessible URIBurner Service.
OpenLink Structured Data Sniffer (OSDS)
OSDB performed the following tasks:
-
Queried the Virtuoso instance behind the URIBurner service for entities matching terms in the target document
-
Applied a Highlight and a Hyperlink to each matched entity
-
Opened up a table comprising matched entities and their types when each highlighted entity was clicked
-
Opened up an Entity Description page when a link in the table was clicked
OpenLink Structured Data Bot (OSDB)
OSDB performed the following tasks, using a URIBurner-generated Entity Name as a Data Source Name, which leads into a Knowledge Graph:
-
Retrieved the descriptions of available Actions
-
Used the Action Descriptions to generate invocation consoles
OpenLink SPASQL Query Builder (OSQB)
The SPASQL Query Builder performed the following tasks, courtesy of Virtuoso’s Multi-Model DBMS architecture:
-
Created a Virtual Relation targeting data from an external source (in this case the URIBurner Service), using a Federated SPARQL Query
-
Nested the Virtual Relation within the
FROMclause of a SQL statement -
Presented a Query Solution in Tabular Form, comprising Hyperlink-based Super Keys that each resolve to a description of the entity they identity
Related Pages
- Web Data Commons Stats for 2020
- MarketBeat Article about AMC — https://www.marketbeat.com/stocks/NYSE/AMC/
- HTML Document Description by URIBurner — http://linkeddata.uriburner.com/about/html/https/www.marketbeat.com/stocks/NYSE/AMC/
- Entity Name (or Identifier) for the Web Page that doubles as a Data Source Name into a Knowledge Graph — http://linkeddata.uriburner.com/about/id/entity/https/www.marketbeat.com/stocks/NYSE/AMC/