Sponger: Stateless Linked Data Generation
- Stateless Linked Data Generation
Stateless Linked Data Generation
Prior to Virtuoso Release 7.2, Linked Data generation by the Sponger was stateful in the sense that the Sponger always saved the generated RDF to the Virtuoso quad store. In addition to this stateful mode, Release 7.2 introduces stateless Sponger transformations.
With a stateless transformation, the Sponger returns its output directly to the client without saving the generated RDF to quad store.
Stateful and Stateless Transformation Modes Compared
Stateful Transformation
- Performed through the
/aboutor/describeendpoints, or through SPARQL sponging extensions. - The generated RDF is saved to the Virtuoso quad store in a graph with a URL matching the URL of the sponged data source.
- The generated RDF is not returned directly to the client. The client must make a separate request to retrieve the data from the quad store through one of numerous retrieval options - URL dereference, SPARQL, Virtuoso Linked Data viewers (
/about,/describe,/fct, ODE) etc. - The extractor and meta cartridges are invoked in an implicit pipeline. Typically one extractor cartridge will be invoked, followed by multiple meta cartridges. Which cartridges are invoked is determined by the data source URI and the content MIME type.
!

Stateless Transformation
- Performed through new
/ext,/ext-async,/enror/enr-asyncendpoints./extand/ext-asyncsupport synchronous and asynchronous RDF generation through the Sponger extractor cartridges/enrand/enr-asyncsupport synchronous and asynchronous enrichment through the Sponger meta cartridges
- The generated RDF is returned directly to the client and not saved to a named graph.
- No implicit transformation pipeline. The client invokes an individual, explicitly identified, cartridge.
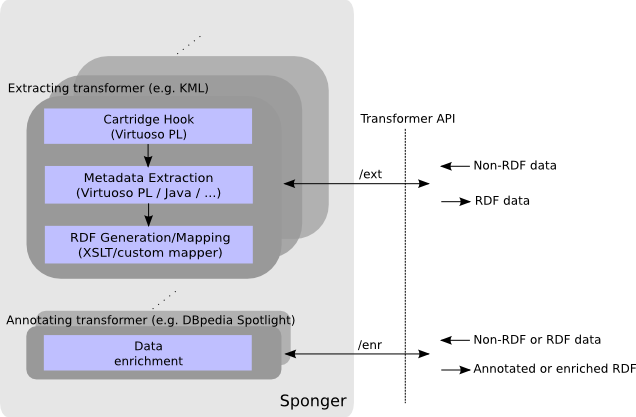
Virtuoso Endpoints for Stateless Linked Data Generation
The four new Sponger transformation endpoints introduced in Release 7.2, /ext, /ext-async, /enr and /enr-async, all expose the same RESTful Transformer API which supports GET requests for obtaining a description of a transformer, and POST requests for transforming the supplied content. In the context of the Transformer API, the term “transformer” spans both extractors (aka extractor cartridges), which transform non-RDF data to RDF, and enrichers (aka meta cartridges) which enrich the supplied content in some way, and which may or may not be RDF.
The new endpoints provide a much more loosely coupled “transformation middleware”, allowing a client to control exactly which transformers to invoke and choice over how, where, and if, the transformation output is saved. Stateless transformation supports a more flexible approach to Linked Data generation and processing - for instance, a client application might choose to perform some intermediate processing between calls to successive transformers in a notional transformation pipeline constructed by the application.
RESTful Transformer API
The RESTful transformation services are defined by a Transformer API detailed here. Each cartridge, or transformer, exposes a separate transformation service URI based on a cartridge identifier, for example:
-
CSV extracting transformer:
http://linkeddata.uriburner.com/ext/csvhttp://linkeddata.uriburner.com/ext-async/csv
-
KML extracting transformer:
http://linkeddata.uriburner.com/ext/google-kmlhttp://linkeddata.uriburner.com/ext-async/google-kml
-
DBpedia Spotlight annotating transformer:
http://linkeddata.uriburner.com/enr/dbpedia-spotlight-meta-fusepoolhttp://linkeddata.uriburner.com/enr-async/dbpedia-spotlight-meta-fusepool
A GET request of the resource will return a description of the service. A POST request does the actual transformation of the data. Both synchronous and asynchronous transformation is supported, but a transformer may choose to process a synchronous request asynchronously if it classes the transformation job as ‘long running’. By default, a long running request is one supplying content longer than 8KB. You can override this default threshold through the “asynchronous mode - content length threshold” setting in the Conductor:
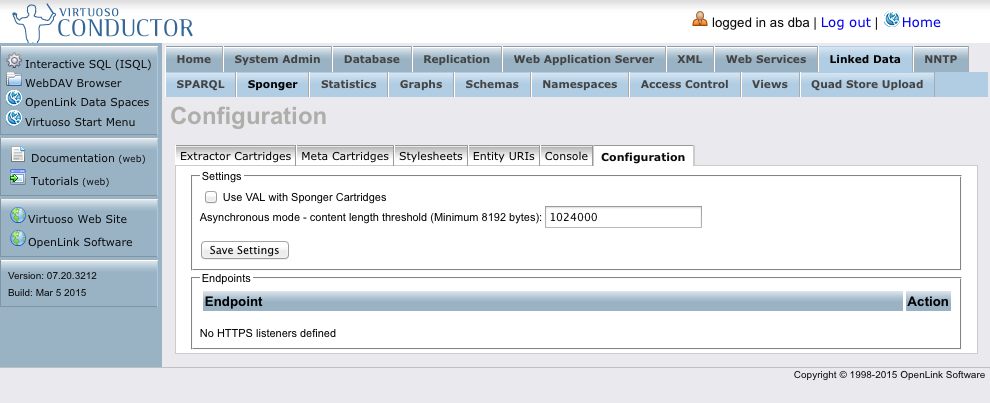
or by setting the underlying Virtuoso registry value directly. For example, to set the threshold to 10MB, execute the following in isql:
registry_set('__ldgen_long_running_threshold', 10485760)
A client can explicitly request asynchronous transformation by using one of the asynchronous endpoints, /ext-async or /enr-async.
A successful synchronous transformation returns HTTP status code 200 (OK) and the transformed content.
Asynchronous transformations return HTTP status code 202 (Accepted) and a job URI in the Location header. Once the job has completed, an HTTP GET of the job URI returns the transformed content and status code 200. While the job is running, HTTP GETs return status 202 and at least the triple:
<{job URI}> trans:status trans:Processing
where prefix trans: is <http://vocab.fusepool.info/transformer#>.
Asynchronous Transformation Result Caching
Though the transformation results from the stateless transformation endpoints are not saved to quad store, Virtuoso caches asynchronous transformation results in a database table to serve future requests for the result. Retrieving a job’s results does not delete the results from the cache, they are kept until expired. The expiry time of the results depends on the time taken for the transformation (30 minutes for each second of execution time); the longer the transformation time, the longer the results are retained, the aim being to minimise the need to reproduce them.
Synchronous Data Transformation
Getting a Description of a Transformer
As per the transformer specification, a GET request will return an RDF description of the transformer.
GET Request:
curl "http://linkeddata.uriburner.com/ext/csv"
GET Response:
@prefix dct: <http://purl.org/dc/terms/>.
@prefix trans: <http://vocab.fusepool.info/transformer#>.
<http://linkeddata.uriburner.com/ext/csv> a trans:Transformer;
dct:title "CSV Extractor";
dct:description "CSV Extractor";
trans:supportedInputFormat "*/*";
trans:supportedOutputFormat "text/turtle";
trans:supportedOutputFormat "application/rdf+xml";
trans:supportedOutputFormat "application/ld+json".
Transforming Data
Generating Linked Data Directly From Content
The following curl examples post data to a transformer for transformation. If trying the examples, you should download the sample CSV files
to the folder in which you’re executing the curl commands.
curl -i -H "Content-Type: text/csv" -H "Accept: text/turtle"
-H "Content-Location: http://linkeddata.uriburner.com/pub" --data-binary @pubs.csv
-X POST "http://linkeddata.uriburner.com/ext/csv"
curl -i -H "Content-Type: text/csv" -H "Accept: application/rdf+xml"
-H "Content-Location: http://linkeddata.uriburner.com/accommodation"
--data-binary @accommodation.csv
-X POST "http://linkeddata.uriburner.com/ext/csv"
The Accept and Content-Location headers are optional. The fallbacks are text/turtle and http://{sponger-host}/entity. The Content-Location header provides a base URI which forms the root of all entity URIs in the generated cartridge output.
Although the call is to a synchronous transformer, it may decide internally that the processing time is potentially large and start the transformation in asynchronous mode. You will then need to make an additional GET request to get the transformation result, as detailed below.
Asynchronous Data Transformation
The /ext-async service always handles requests asynchronously, so transformer http://linkeddata.uriburner.com/ext-async/csv can be used to demonstrate the asynchronous transformation mode.
Getting a Description of a Transformer
This is no different to the synchronous transformer description shown above.
curl -i "http://linkeddata.uriburner.com/ext-async/csv"
Transforming Data
The transformation of the data requires two steps, POSTing the data and GETting the result:
POSTing the data
curl -i -H "Content-Type: text/csv"
-H "Accept: text/turtle; q=1.0, application/rdf+xml; q=0.9, application/ld+json; q=0.8"
-H "Content-Location: http://linkeddata.uriburner.com/pub"
--data-binary @pubs.csv -X POST "http://linkeddata.uriburner.com/ext-async/csv"
curl -i -H "Content-Type: text/csv"
-H "Accept: text/turtle; q=0.8, application/rdf+xml; q=1.0, application/ld+json; q=0.9"
-H "Content-Location: http://linkeddata.uriburner.com/accommodation"
--data-binary @accommodations.csv -X POST "http://linkeddata.uriburner.com/ext-async/csv"
The answer to the request will look similar to this:
HTTP/1.1 202 Accepted
Server: Virtuoso/07.10.3211 (Linux) x86_64-redhat-linux-gnu VDB
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Date: Thu, 30 Oct 2014 11:59:38 GMT
Accept-Ranges: bytes
Location: /ext-async/status/29
Content-Length: 0
Use of Accept and Content-Location headers is optional. The fall-backs are text/turtle and http://{sponger-host}/entity.
GETting the result
The results can be retrieved at the location indicated by the Location header in the response to the POST request.
curl -i "http://linkeddata.uriburner.com/ext-async/status/29"
Listing Transformer Service IDs
Each transformer service is identified by a URI of the form:
http://{sponger-host}/{ext[-async]|enr[-async]/{transformer-service-id}
ending with the transformer’s service ID. The following endpoints:
/transformers/ext(also/transformers/ext-async/)/transformers/enr(also/transformers/enr-async/)
return a list of the available extracting and enriching transformers identified by URIs containing their transformation service IDs.
curl -sS http://linkeddata.uriburner.com/ext/
@prefix dct: <http://purl.org/dc/terms/> .
@prefix trans: <http://vocab.fusepool.info/transformer#> .
<http://linkeddata.uriburner.com/ext/amazon-article> a trans:Transformer ;
dct:description "Amazon articles Extractor" .
<http://linkeddata.uriburner.com/ext/angellist> a trans:Transformer ;
dct:description "Angel List Extractor" .
<http://linkeddata.uriburner.com/ext/bbc-music> a trans:Transformer ;
dct:description "BBC Music Extractor" .
...