In the fast-paced world of artificial intelligence, chatbots using language model strategies are becoming more common. However, these chatbots sometimes generate responses based on incorrect or fabricated information, a problem often referred to as “hallucinations.” This issue can lead to misinformation, confusion, and a less satisfactory experience for users.
Fortunately, there is a solution: incorporating a Knowledge Graph into your chatbot strategy. This method is key to reducing hallucinations and improving the accuracy and reliability of your chatbot. If you’re unfamiliar with this approach, this guide will help you understand and implement it step by step, leveraging knowledge bases constructed using linked data principles that are publicly accessible from the Linked Open Data (LOD) Cloud.
How to Incorporate a Knowledge Graph into Your Chatbot Strategy
- Create and Test a Query for Future Use in Predefined Query Templates: Start by crafting a federated query that taps into LOD Cloud knowledge bases such as UniProt, ChEBI, Rhea, and OMIM. These databases are maintained by experts in their respective fields, ensuring high-quality and reliable information.
- Develop a Query Template: This template follows a straightforward format: {sentence} : {query}. It utilizes the language model’s ability to analyze sentence similarity, ensuring that different sentence variations trigger the execution of the intended query.
Example of Creating and Registering a Predefined Query Template
Find all human UniProtKB entries that are annotated to be involved in a disease and are enzymes catalyzing reactions where a substrate or product has a Cholestane substructure:
PREFIX taxon: <http://purl.uniprot.org/taxonomy/>
PREFIX sachem: <http://bioinfo.uochb.cas.cz/rdf/v1.0/sachem#>
PREFIX rh: <http://rdf.rhea-db.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX up: <http://purl.uniprot.org/core/>
SELECT *
WHERE {
SERVICE <https://sparql.uniprot.org/> {
SELECT ?protein ?disease ?rhea ?chebi ?omim
WHERE {
# Find complete ChEBIs with a Cholestane skeleton, via the Czech Elixir node IDSM Sachem chemical substructure search.
SERVICE <https://idsm.elixir-czech.cz/sparql/endpoint/chebi> {
?chebi sachem:substructureSearch [
sachem:query
"[C@]12(CCC3CCCC[C@]3(C)[C@@]1([H])CC[C@]1(C)[C@@]([H])([C@@](C)([H])CCCC(C)C)CC[C@@]21[H])[H]"
].
}
# Use the fact that UniProt catalytic activities are annotated using Rhea
# Mapping the found ChEBIs to Rhea reactions
SERVICE <https://sparql.rhea-db.org/sparql>{
?rhea rh:side/rh:contains/rh:compound/rdfs:subClassOf ?chebi .
}
# Match the found Rhea reactions with human UniProtKB proteins
?protein up:annotation/up:catalyticActivity/up:catalyzedReaction ?rhea .
?protein up:organism taxon:9606 .
# Find only those human entries that have an annotated related disease, and optionally map these to OMIM
?protein up:annotation/up:disease ?disease .
OPTIONAL {
?disease rdfs:seeAlso ?omim .
?omim up:database <http://purl.uniprot.org/database/MIM>
}
}
}
}
- Generate Ten Sentence Variations for the Predefined Query Template: Use ChatGPT or a similar tool to create ten different ways to express the query’s purpose. This ensures flexibility in how queries can be initiated.

- Use a Sentence Variation with the Predefined Query Template: Select one of the sentence variations and use it in a chatbot prompt.
“Locate all human UniProtKB proteins related to diseases that facilitate reactions with substrates or products containing a Cholestane substructure. Apply a timeout of 30000 to the underlying query used to answer the question.”
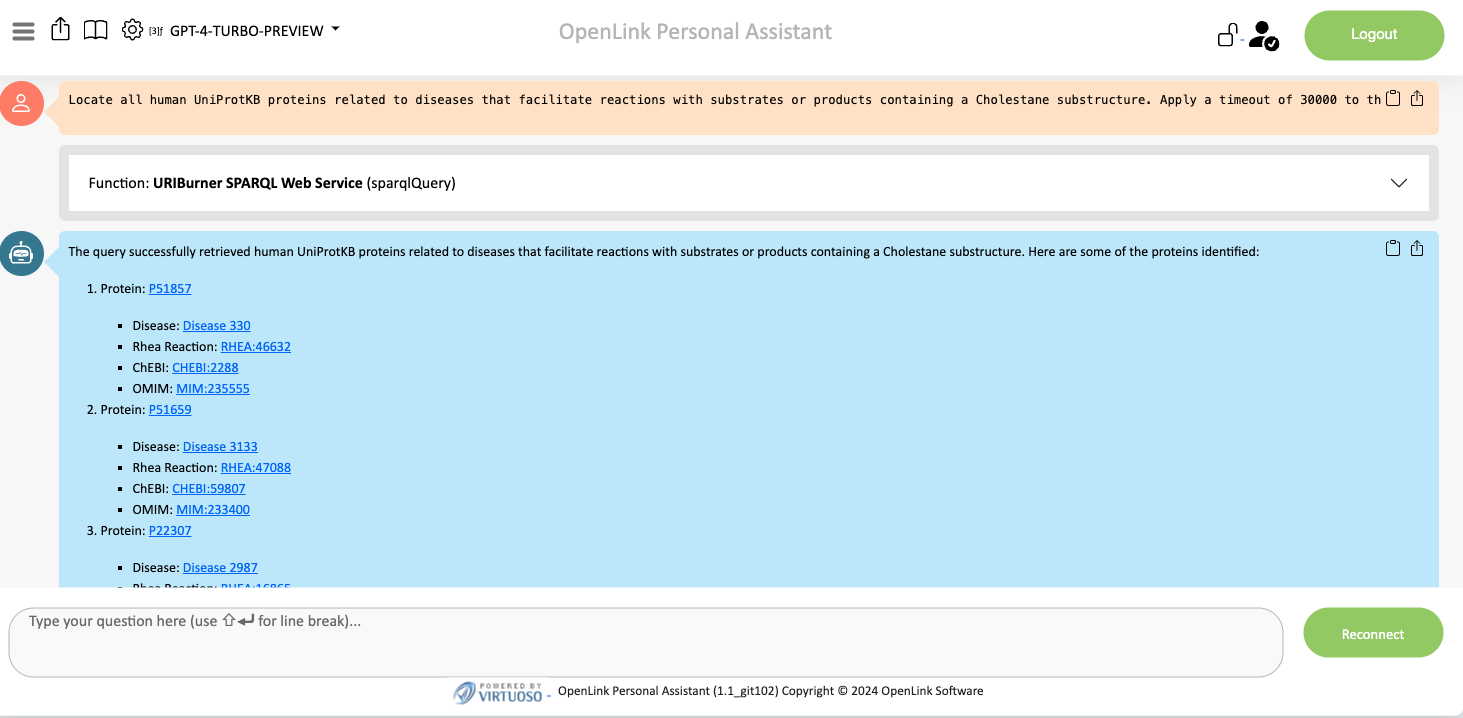
- Try Another Sentence Variation: For diversity, use a different sentence variation for another query.
“Retrieve all human UniProtKB entries implicated in diseases and serve as enzymes for reactions with substrates or products featuring a Cholestane substructure. Also apply a timeout of 30000 when producing the answer.”

Conclusion
Using predefined query templates linked to expert-curated knowledge bases presents an effective strategy to minimize inaccuracies in language model-based chatbots. This approach significantly enhances both the reliability and the user experience of your chatbot.
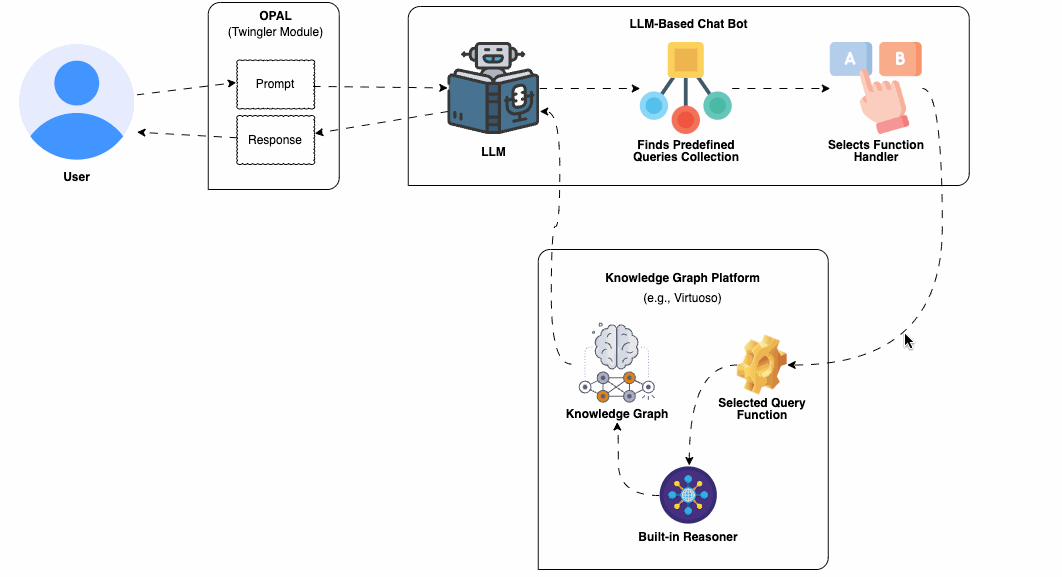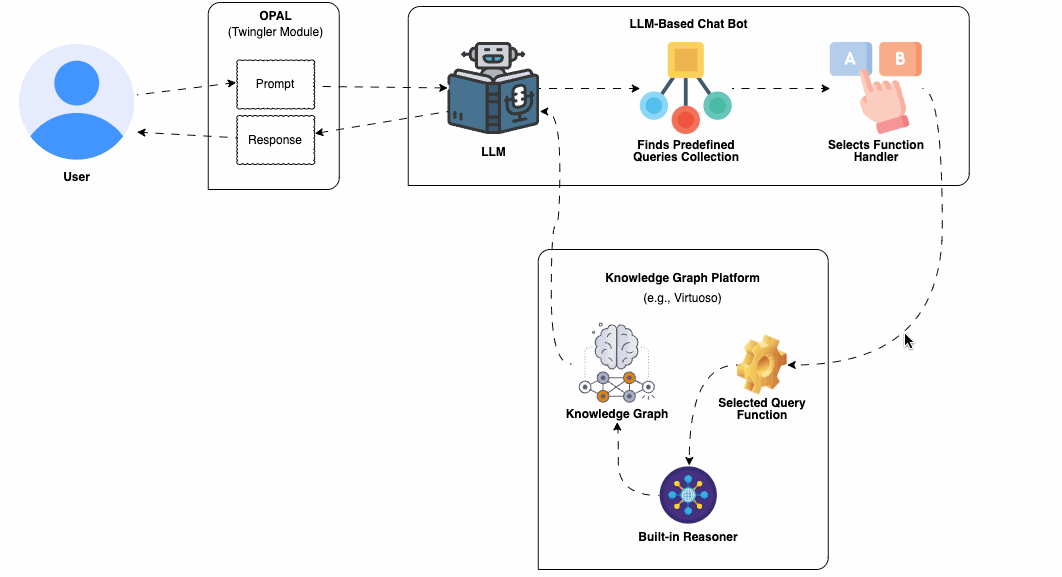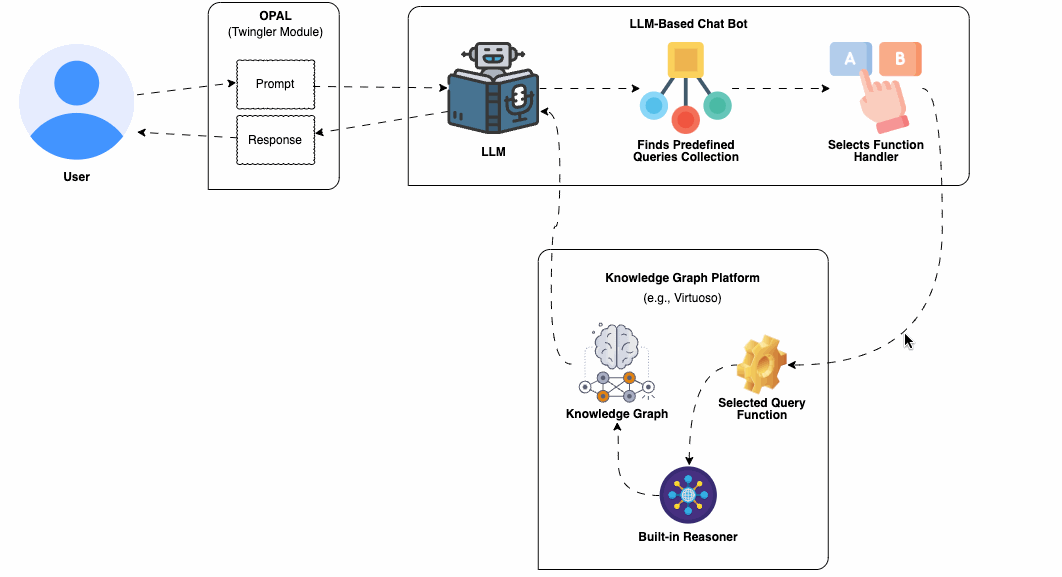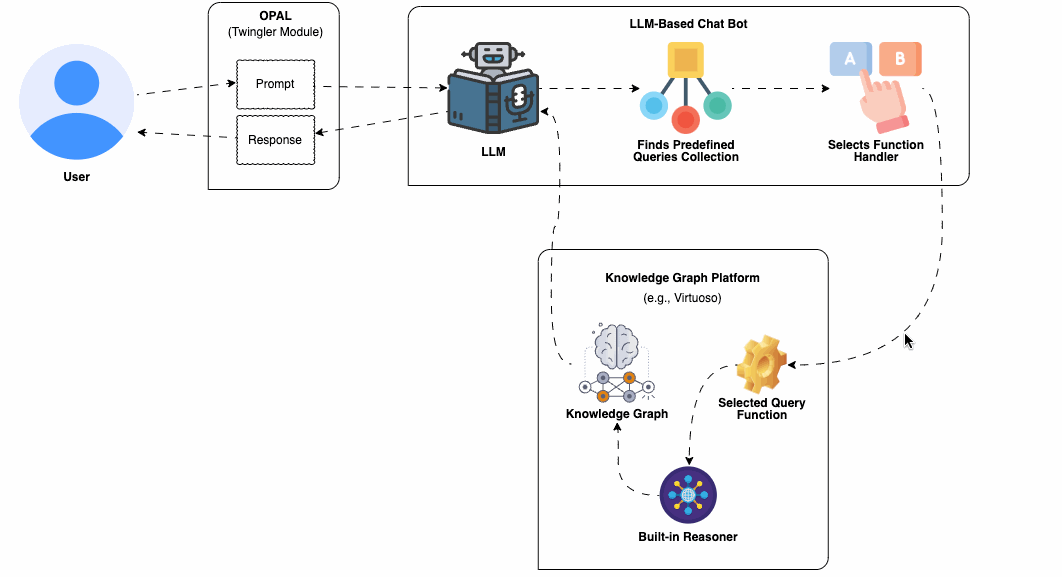
An important advantage is the extensive collection of domain-expert curated knowledge bases that have been systematically published to the Web as Knowledge Graphs. This has been part of the broader initiative of the Linked Open Data Cloud collective for several years. Each Knowledge Graph is accessible through a SPARQL Query Service, enabling interaction via a fully-fledged declarative query language that adheres to open standards. Furthermore, these query endpoints typically come equipped with a collection of sample queries, crafted by experts, which can be readily utilized to implement the predefined query template approach discussed in this guide. This serves as a cornerstone in a strategy aimed at minimizing hallucinations, thereby ensuring the delivery of accurate and reliable information through your chatbot.
Related
- OpenLink Personal Assistant Session Transcript Demonstrating Predefined Query Templates using a Federated SPARQL Query over Uniprot, RHEA, ChEBI, and OMIM
- Using SPARQL Query Templates to Fine-Tune ChatGPT’s Large Language Model (LLM)
- Solving Terminology Bloat via a Semantic Web and LLM-based Chat Bot Symbiosis | LinkedIn
- Generating an FAQ and Defined Terms Knowledge Graph from a LinkedIn Post | LinkedIn