Prerequisites:
- A free or premium account on Airtable
- Access to a public or private SPARQL endpoint
Creating a CSV Document with Virtuoso for Airtable Public
We will use a Virtuoso-generated CSV document for this exercise as neither ODBC nor JDBC connections are currently supported by Airtable, which is typical of a cloud hosted application.
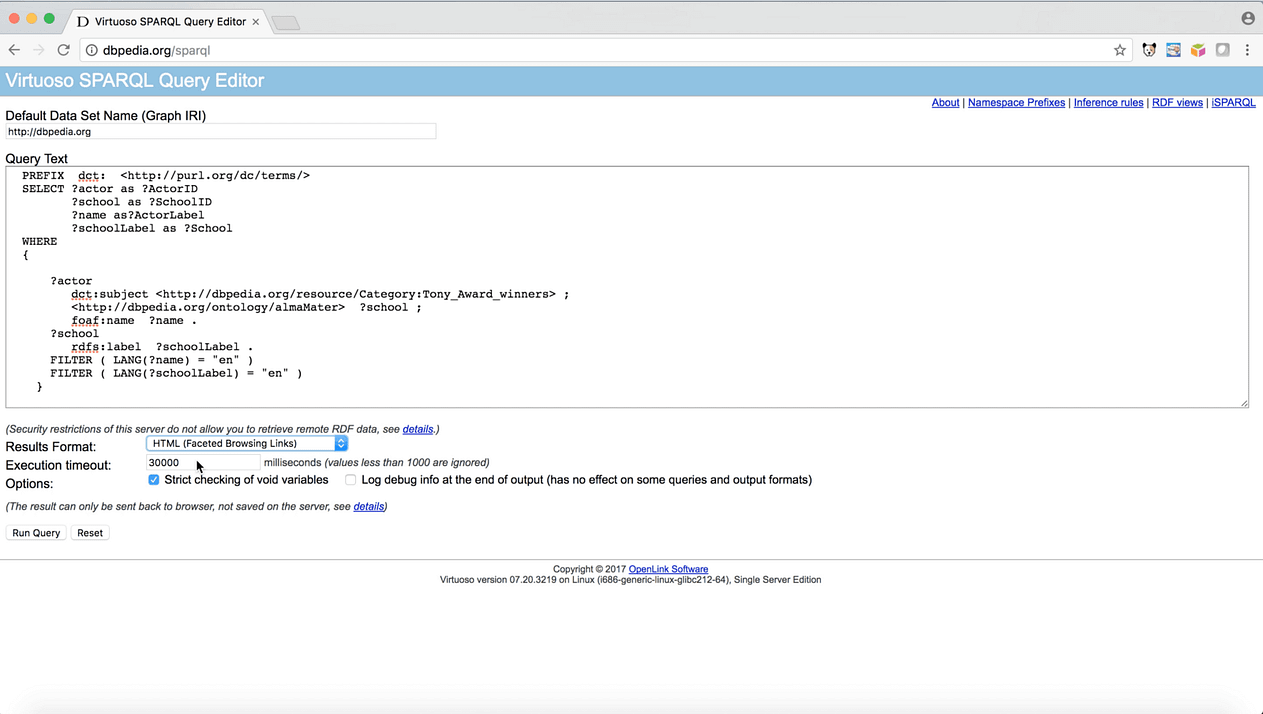
[1] Navigate to DBPedia’s public SPARQL endpoint and enter the query below (or use this pre-populated form):
PREFIX dct: <http://purl.org/dc/terms/>
SELECT ?actor AS ?ActorID
?school AS ?SchoolID
?name AS ?ActorLabel
?schoolLabel AS ?School
WHERE
{
?actor
dct:subject <http://dbpedia.org/resource/Category:Tony_Award_winners> ;
<http://dbpedia.org/ontology/almaMater> ?school ;
foaf:name ?name .
?school
rdfs:label ?schoolLabel .
FILTER ( LANG(?name) = "en" )
FILTER ( LANG(?schoolLabel) = "en" )
}
ORDER BY ASC(?school)
LIMIT 100
[2] Ensure that the Results Format menu selection is HTML (Faceted Browser Links) , and click the Run Query button.
[3] An HTML table will be populated with the SPARQL query’s results.
- Query Editor : http://tinyurl.com/yatubfkc
- Query Results : http://tinyurl.com/ybv7wnh6
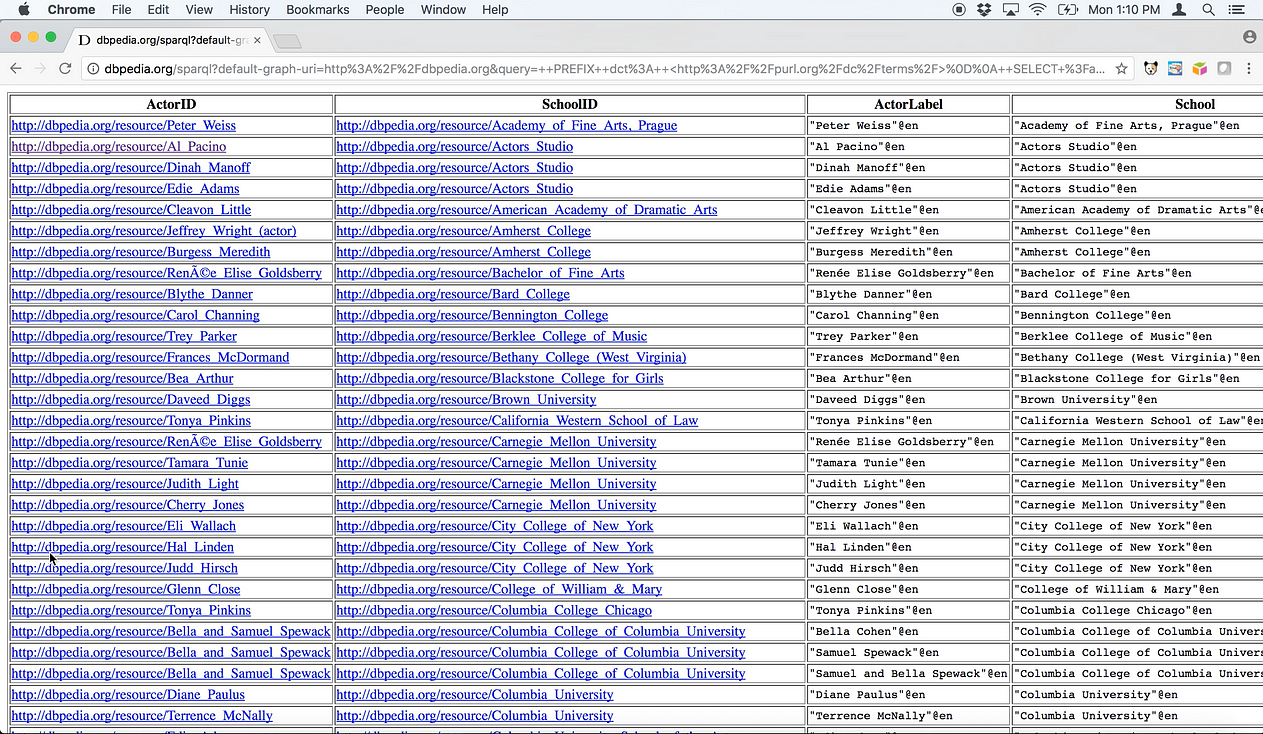
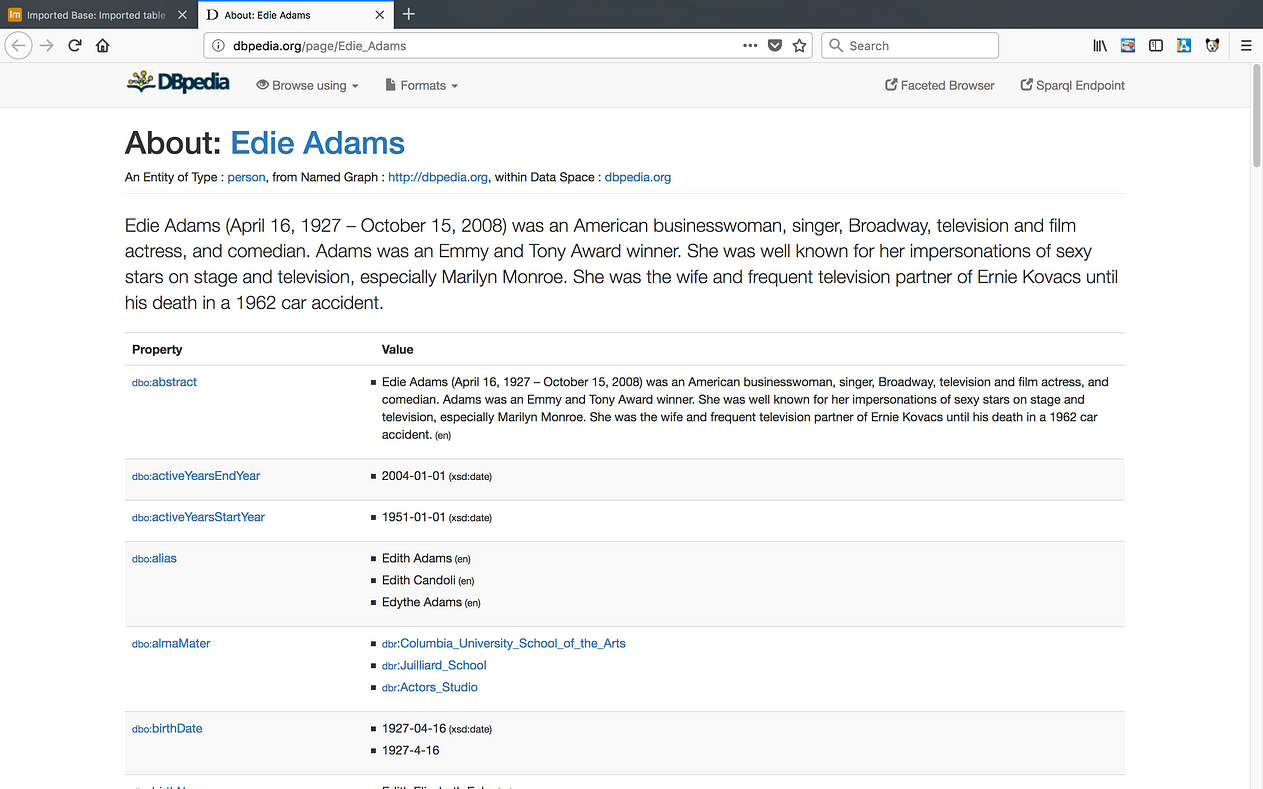
[4] Click on any ActorID URI (for example, http://dbpedia.org/resource/Al_Pacino ) to confirm that the URIs resolve. Each URI will open a page from DBpedia that describes that actor using a collection of attribute and value pairings, as depicted below.

[5] Use the Back button in your browser to return to the query editor, and change the Results Format menu selection to CSV; then click Run Query.
[6] A CSV document populated with results from the SPARQL query will be either displayed in your browser or saved to your normal downloads folder, depending on your browser’s capabilities and settings.

Airtable Data Usage
[7] Bring up Airtable in your browser, click to the Bases section, and click New Table → Import from Spreadsheet .
[8] Paste your CSV data, or choose a CSV document on your local machine or an Airtable-supported host (e.g., Google Drive).
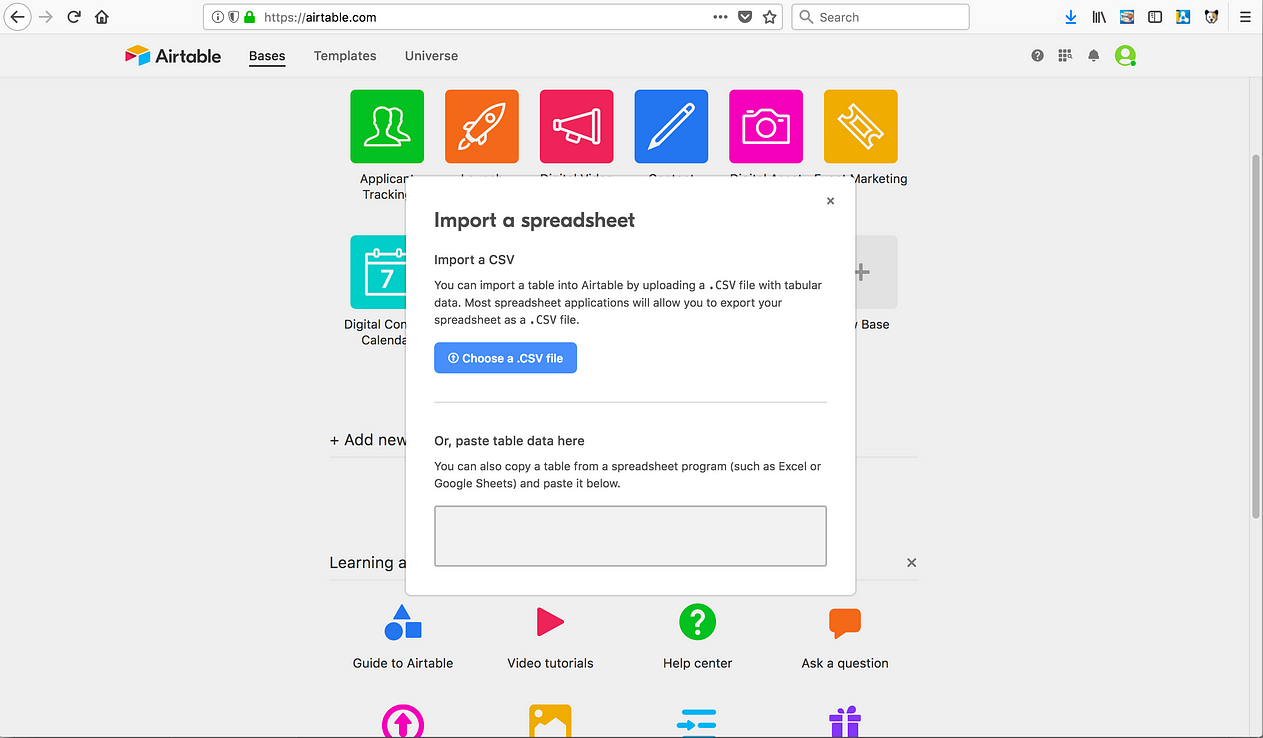
[8a] Note: Virtuoso also enables you to leverage WebDAV to access your CSV document, if it’s been stored on a host that’s not Airtable-supported .

CSV Document in a local folder mounted via WebDAV scoped to a Virtuoso instance
[9] Click on the newly generated icon for your Spreadsheet (here, it’s the blue box labeled with " Ac ").
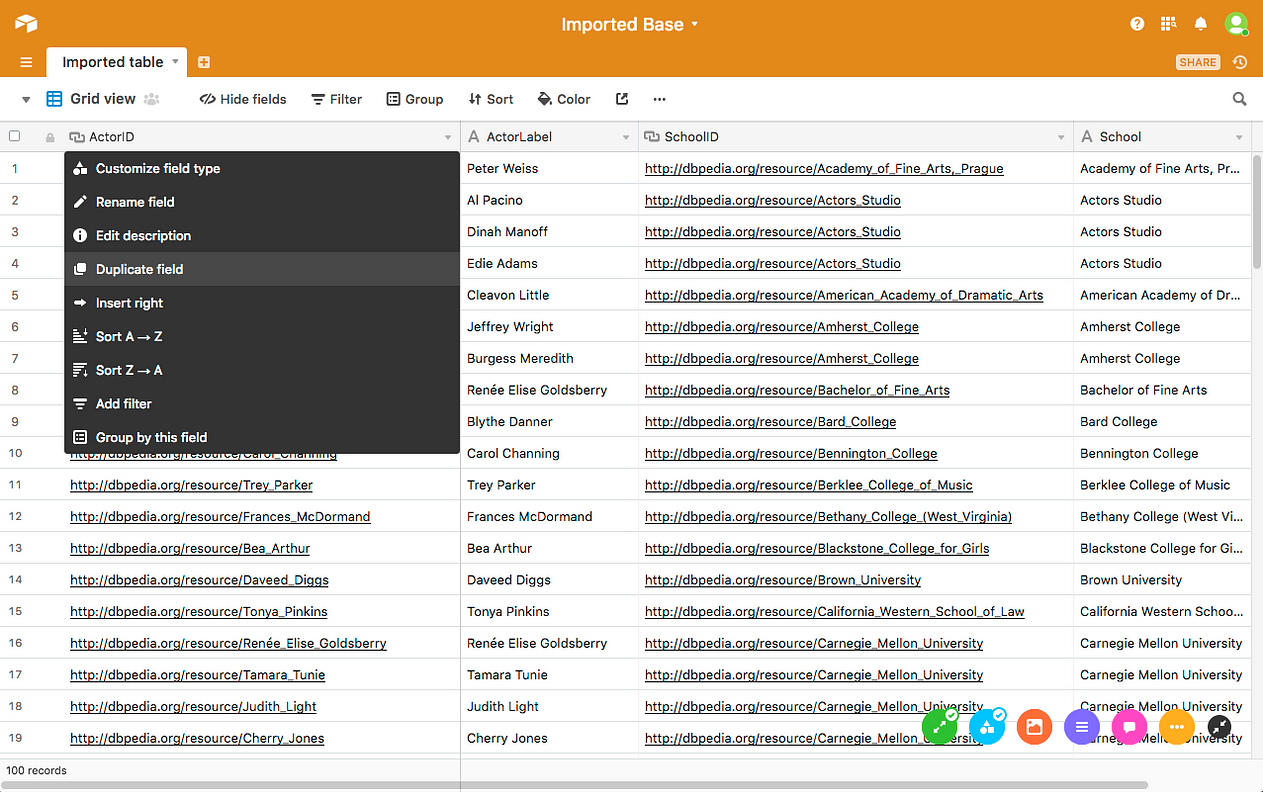
[10] Because Airtable considers ActorID to be the Primary Field (more commonly called a Primary Key) that uniquely identifies records in this document, the HTTP URIs are not clickable as such. To enable this functionality, we will need to copy these values to a new column. Right-click (or control-click) on the ActorID column name, and select Duplicate field .
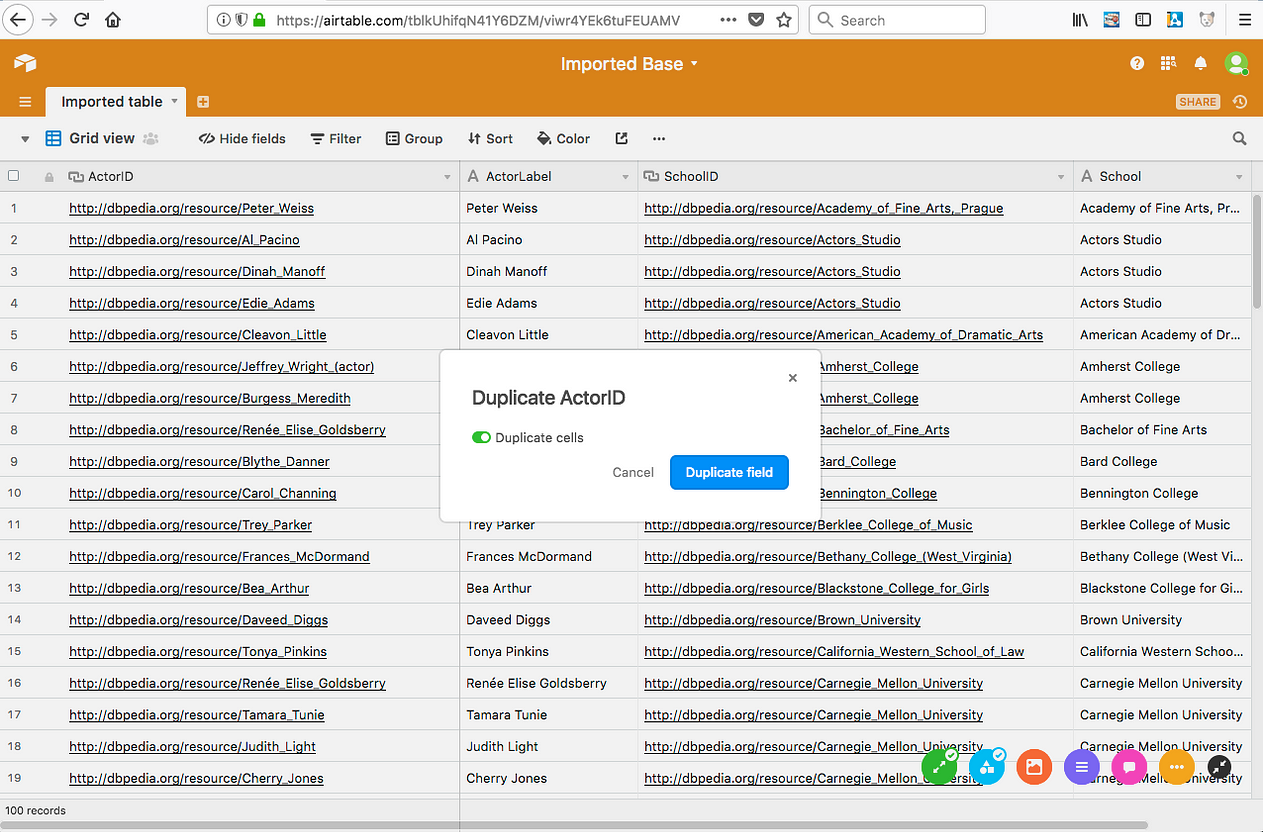
[11] Ensure Duplicate cells is selected, and click Duplicate field .
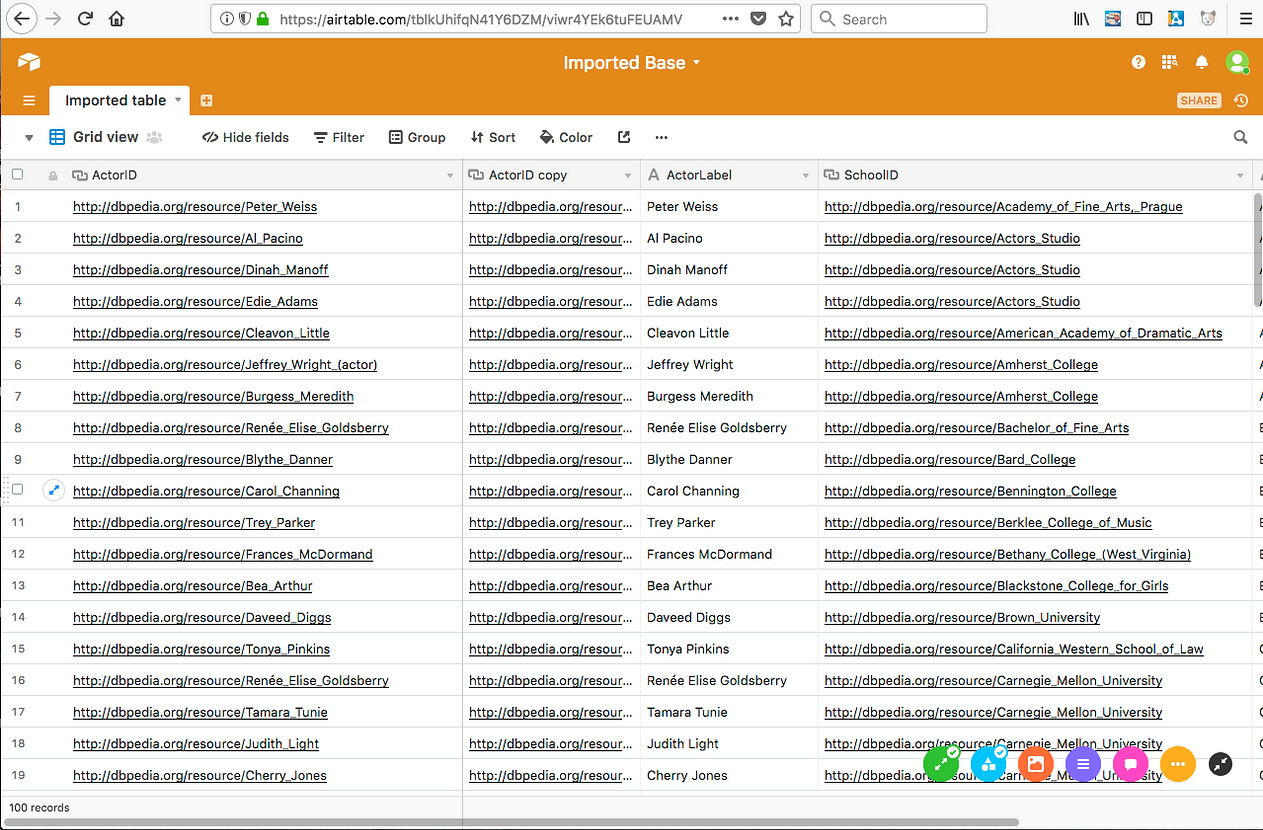
[12] Once the duplication process is completed, click the header of the ActorLabel column, and copy the entire column to your clipboard.
[13] Click the header of the ActorID column and click Paste . Confirm the content replacement when prompted.
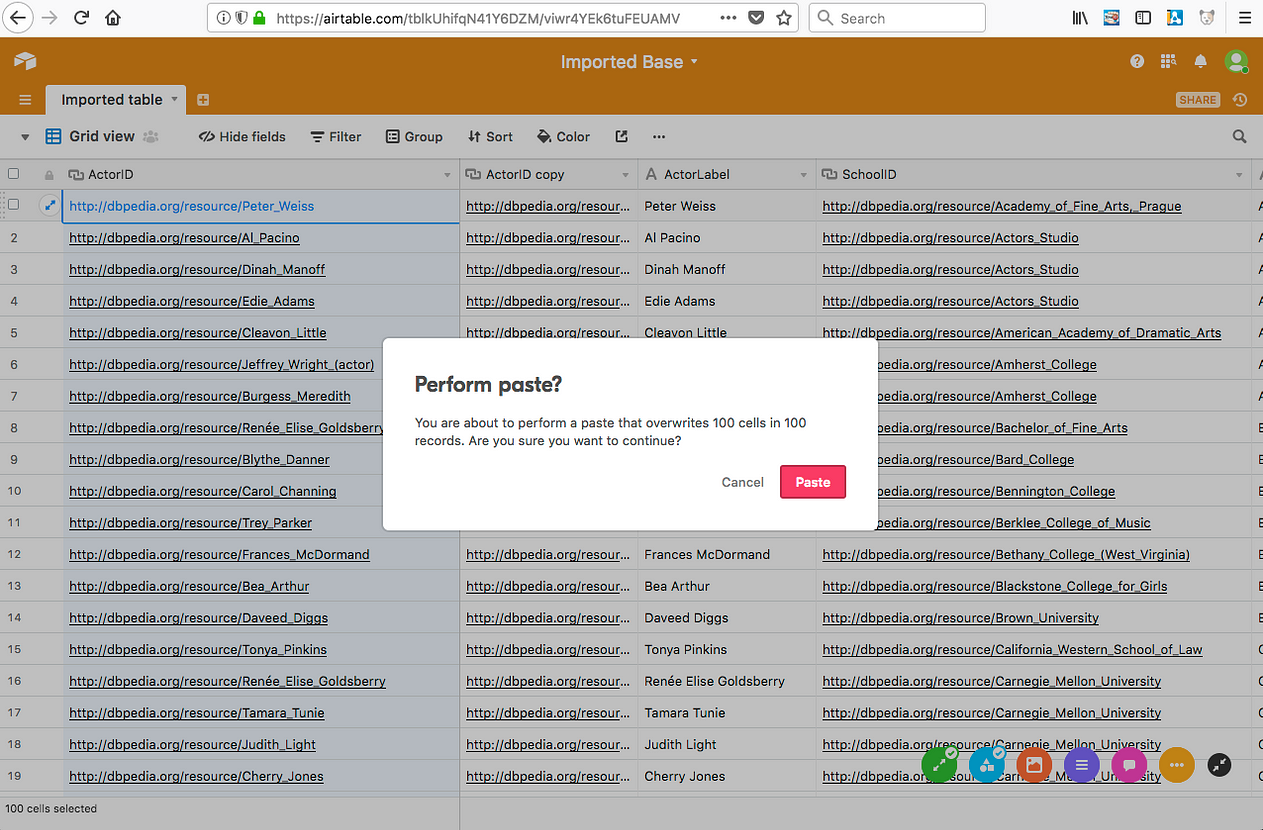
[14] All of the cells in the column will be replaced, including the column name. Right-click (or control-click) on the ActorLabel column header, and choose Delete field .

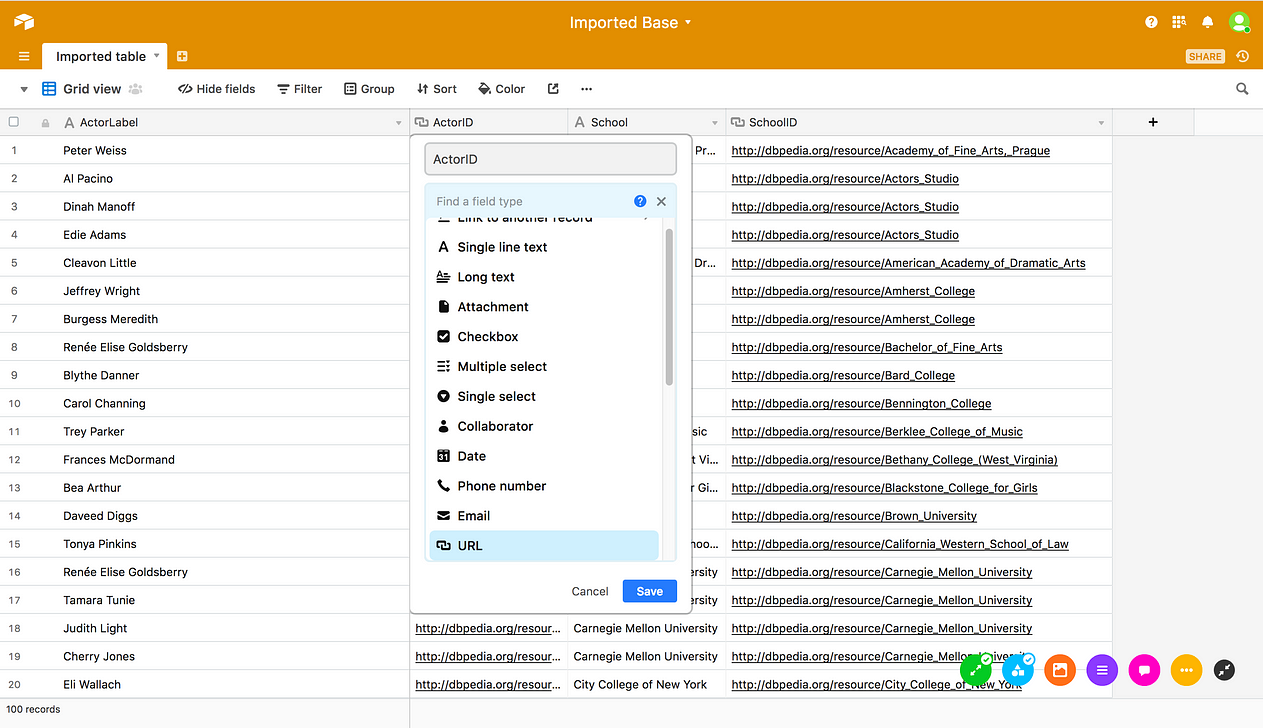
[15] Double-click on the ActorID column header; select URL from the drop down menu; and click Save .
[16] Double-clicking on a cell within the ActorID column will now open a new browser tab containing the content of the URI described.
[17] Repeat step 15 on the SchoolID column.
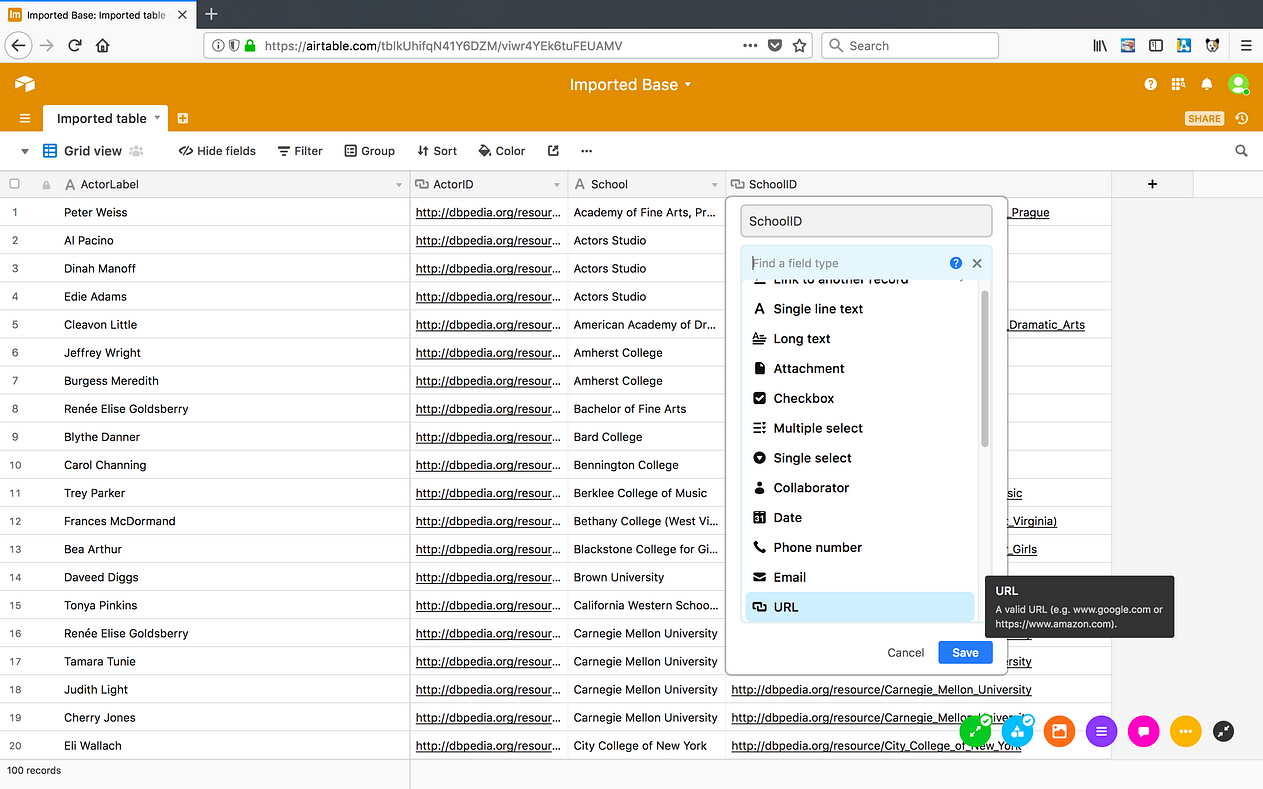
[18] Double click on any URI in the SchoolID column to confirm that it resolves to a DBPedia page.

Conclusion
This post demonstrates how Virtuoso can be used to enhance an existing productivity tool (in this case, Airtable) by injecting Super Keys (in the form of DBpedia identifiers [HTTP URIs]) into SPARQL Query Results saved to a CSV document.
This evolves Airtable into a productivity tool for non-programmers that provides a Semantic Web of Linked Data exploration launch-point as an added enhancement to its built data visualization functionality.
Finally, this exercise demonstrates how an existing end-user productivity tool can harness the power of Linked Data without the need for expensive and failure-prone “rip and replace” misadventures.
Related
- About Virtuoso Universal Server
- Using Virtuoso and the ODS-Briefcase Module to access documents from a variety of Third Party Storage Services
- Maintaining a Google Spreadsheet about Market Segmentation, Dynamically
- Using Tableau (Public Edition) as a Launch Point for Exploration of a Semantic Web of Linked Data
- Using Microsoft Power BI Reports & Dashboards as a Launch Point for Exploration of a Semantic Web of Linked Data
- Using Yellowfin BI as a Launch Point for Exploration of a Semantic Web of Linked Data
- LOD Cloud Connectivity License for ODBC, JDBC, and ADO.NET — provides connectivity to the massive Linked Data Cloud via our URIBurner Service
- URIBurner Service — free service provides Linked Data Cloud Access and 5-Star Linked Data Extract, Load, and Transformation (ETL) Services
- OpenLink Data Access Drivers for ODBC, JDBC, ADO.NET, and OLE DB