
This plugin offers full SPARQL Protocol functionality as defined by the W3C open standard. It also includes support for SPARQL-FED, which enables the seamless integration of any SPARQL Query Service endpoint that allows SPARQL access using this method.
Benefits
This plugin facilitates access to data from diverse sources that are HTTP-accessible. This means you can harness the power of natural language for generating queries across various data sources on both public and private networks.
Concerning private use and data privacy issues, an FAQ section is provided to address such concerns.
SQL & SPARQL Background
Basic Introduction
SPARQL is a declarative, structured query language from the W3C, significantly influenced by SQL, due to its wide installation base. Like SQL, SPARQL can be used to create, read, update, and delete data represented as entity-relationship types (relations). However, unlike SQL, SPARQL leverages HTTP as its native wire-protocol and incorporates federation as a core functionality.
SPARQL provides a query language for both the World Wide Web and its Linked Open Data (LOD) Cloud enclave. This language enables the development and deployment of modern solutions compatible with any HTTP-aware app or service, while also providing access to data from a variety of sources.
Query Language Utility Comparison
Here’s a straightforward comparison of both the SQL and SPARQL query languages, highlighting their differences in terms of functionality offered.
| Issue | SQL | SPARQL |
|---|---|---|
| Relations Structure | Table | Entity Relationship Graph |
| Query Solution Structure Types | Table | Table or Entity Relationship Graph |
| Federation | Partial and DBMS specific | Yes (courtesy of SPARQL-FED) |
| Data Source Names (DSNs) Types | X.500 Names, URLs (for JDBC) | Internationalized Resource Identifiers (IRIs) which may be HTTP-based |
| Reasoning & Inference | Limited to View Definitions | Yes, only limited by logic expression imagination |
| Usage & Familiarization | Broad | Narrow (but upcoming) |
| Data Access Scope | Centralized around a specific DBMS instance | Decentralized due to support of HTTP-based Hyperlinks as Identifiers functioning as Data Source Names (DSNs) which are crawlable within query solution production pipelines * |
| Data Access Protocols | ODBC, JDBC | ODBC, JDBC, HTTP * |
| Data Governance | Role-based Access Controls (RBAC) | Role-based or Attribute-based Access Controls (ABAC) |
- implies support by the Virtuoso Platform’s implementation of SPARQL
Setup
You start by initializing a GPT-4 session and selecting Plugins mode. Once selected, you navigate to the Plugin Store and search on “SPARQL” to locate the SPARQL Plugin. Select it by hatching its associated checkbox.
Here’s a collection of screenshots depicting the usage flow.
Query Text

Query Processing
Optional Query Processing Debug Info
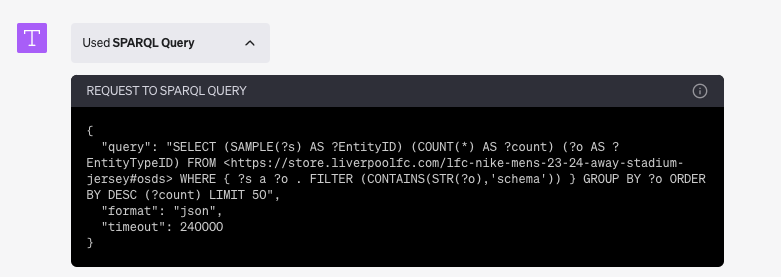
Optional Query Solution Debug Infor
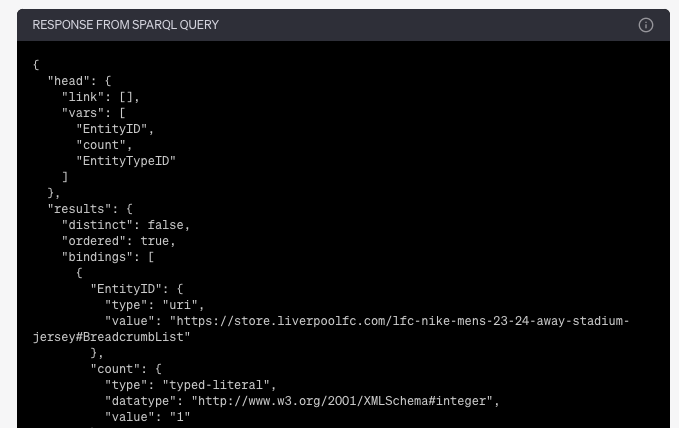
Query Solution
Plugin Use
Now that your GPT-4 session is initialized, set your default behavior preferences as an instruction to be used across all plugin invocations, as per the following prompt examples:
Example 1
Assistant, please remember to always execute SPARQL queries with the following settings:
- Set the format to “text/x-html+tr”.
- Present the query results using an inline table (not HTML).
- Set the timeout to 60000.
- When presenting the results, please make sure to use the /describe based links as the href for the original values using the domain of the default query service as the base.
Example 2
Please execute a SPARQL query to fetch the first 10 books written by author ‘J.K. Rowling’. Set the format to ‘text/x-html+tr’, use an inline table to present the results (not HTML), and set the timeout to 60000. Also, when presenting the results, please make sure to use the /describe based links as the href for the original values.
Example 3
Assistant:
Whenever a SPARQL-FED query is executed, always set the format parameter value to “text/html” by default.
Example 4
Henceforth, whenever I request a SPARQL query to be executed with a designated endpoint, treat the request as a SPARQL-FED request where the designated endpoint is used for the SERVICE associated with designated query. Also note, the SERVICE block must comprise a SELECT Query.
Additional Usage Examples
Basic Prompts
- Write and execute a sample SPARQL query.
SPARQL-FED Prompt Examples
- Write and execute a sample SPARQL query using the DBpedia SPARQL Query Service Endpoint.
- Write and execute a sample SPARQL-FED query using the DBpedia SPARQL Query Service Endpoint.
- Multi-endpoint example using DBpedia and Wikidata
# Mountaineers that died on Mount Everest ordered by their death date:
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX dbc: <http://dbpedia.org/resource/Category:>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
SELECT DISTINCT ?item ?wditem ?wditemLabel ?date WHERE {
SERVICE <http://dbpedia.org/sparql> {
?item dct:subject dbc:Mountaineering_deaths_on_Mount_Everest ;
owl:sameAs ?wditem .
FILTER regex(?wditem, "wikidata.org").
}
SERVICE <https://query.wikidata.org/sparql> {
?wditem wdt:P570 ?date .
OPTIONAL { ?wditem wdt:P18 ?image . }
?wditem rdfs:label ?wditemLabel .
FILTER (LANG(?wditemLabel) = "en").
}
}
ORDER BY ?date
Introspective (Knowledge Graph Exploration) Query Prompts
These are SPARQL Queries that provide results pages for self exploration of the Knowledge Graphs associated with a SPARQL endpoint.
- Sample Named [Knowledge] Graph
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <https://twitter.com/kidehen/status/1682140559157100544#osds>
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
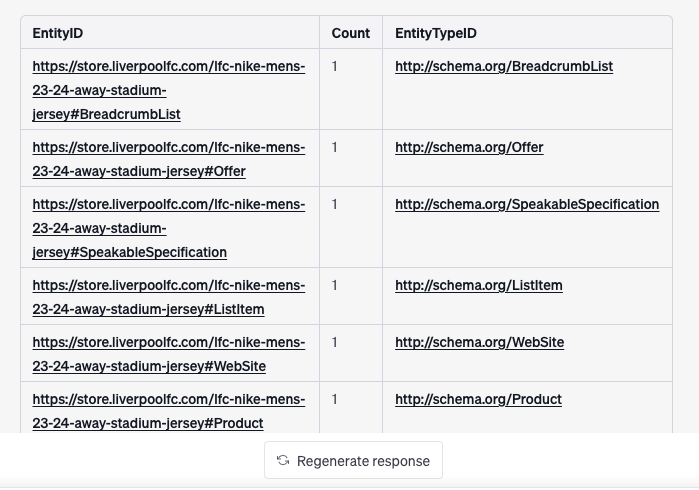
- Offers
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <https://store.liverpoolfc.com/lfc-nike-mens-23-24-away-stadium-jersey#osds>
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
- Offers & FAQs
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <https://virtuoso.openlinksw.com/pricing/#osds>
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
- How-To Guides
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <https://virtuoso.openlinksw.com/howto/>
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
- FAQs
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <https://virtuoso.openlinksw.com/faq-for-cios-cdos/#osds>
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
- Instropection against a known Knowledge Graph comprising a rich variety of entity types
SELECT (SAMPLE(?s) AS ?EntityID)
(COUNT(*) AS ?count)
(?o AS ?EntityTypeID)
FROM <urn:schemaorg:data:abox>
WHERE { ?s a ?o. FILTER isIRI(?s) FILTER isIRI(?o) }
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50
Fine-tuning Query Template Prompts
The following are examples of sparql-based fine-tuning oriented queries that you can use to enrich your ChatGPT session. All you have to do is add them to the session using the prompt: add the following {template-text} to the template collection.
Offers
List offers and prices associated with knowledge graph , using terms from schema.org;SELECT ?offer ?price FROM WHERE { ?offer a schema:Offer; schema:price ?price .} ORDER BY ASC (?price)
HowTos
List HowTo guides associated with knowledge graph , using terms from schema.org;
SELECT ?guide ?step ?name ?text FROM WHERE {
?guide a schema:HowTo;
schema:step ?step.
?step (schema:name|schema:text) ?text.
?guide (schema:name|schema:title) ?name.
}
ORDER BY ASC(?name)
FAQs
List FAQs associated with knowledge graph , using terms from schema.org;SELECT ?page ?question ?name ?answerText FROM WHERE { ?page a schema:FAQPage; schema:mainEntity ?question. ?question (schema:name|schema:title) ?name; (schema:acceptedAnswer|schema:suggestedAnswer) ?answer. ?answer schema:text ?answerText.} ORDER BY ASC (?name)
Job Postings
List Job Postings associated with knowledge graph , using terms from schema.org;SELECT DISTINCT ?job ?name FROM WHERE { ?job a schema:JobPosting; (schema:name|schema:title) ?name. } ;
DBpedia
Add the following template.
What is the country of <A>?:
PREFIX dbr: <http://dbpedia.org/resource/>
PREFIX dbo: <http://dbpedia.org/ontology/>
SELECT ?country
WHERE {
<A> dbo:country ?country.
?country a dbo:Place.
} ;
Frequently Asked Questions
Q: What’s the sole purpose of this plugin?
A: Adding SPARQL Query Execution functionality to ChatGPT, for use in conjunction with its other capabilities.
Q: Since the underlying query service is bound to URIBurner, does that make this a Virtuoso-specific SPARQL Query Service?
A: No, it supports the use of SPARQL-FED for working with any SPARQL-compliant query service e.g., those associated with the massive Linked Open Data (LOD) Cloud Knowledge Graph.
Q: What SPARQL Query Parameters are supported?
A: Query, Format, and Timeout.
Q: Can I update functionality e.g. add more query parameters without having to resubmit the plugin?
A: Yes, simply update the YAML service description associated with the Plugin Manifest.
Q: Can I use this plugin in a totally private setting where interaction is strictly with my internal enterprise knowledge graph?
A: Yes, but you would need a port of the SPARQL plugin for ChatGPT for the Microsoft Azure variant which can be instantiated specifically for your private use i.e., data doesn’t go to OpenAI or URIBurner as part of the query solution production pipeline.
Q: Since the SPARQL Query Service is described via a YAML doc (https://linkeddata.uriburner.com/openapi/sparql-service.yaml), shouldn’t I be able to also use it for external function invocation using the OpenAI External Function calling feature?
A: Yes, simply run the following from iSQL (Conductor or Command-line interface):
SELECT OAS_IMPORT (HTTP_CLIENT(‘https://linkeddata.uriburner.com/openapi/sparql-service.yaml’), ‘UB’);
and then run the Stored Procedure that it generates.
Example:
CREATE PROCEDURE "UB".DBA."sparqlQuery" (IN "query" VARCHAR, IN "format" VARCHAR default null) {
--## SPARQL Query Web Service API, parameters: `query` - the SPARQL query, `format` - the desired response format
DECLARE result, headers, response any;
DECLARE url, request, multipart, "apiKey" varchar;
multipart := request := headers := null;
url := 'https://linkeddata.uriburner.com/sparql';
url := WS.WS.URI_ADD_PARAM (url, 'query', "query");
url := WS.WS.URI_ADD_PARAM (url, 'format', "format");
url := WS.WS.URI_ADD_PARAM (url, 'timeout', 10000);
result := HTTP_CLIENT_EXT (url, http_method=>'GET', http_headers=>headers, body=>request, headers=>response, n_redirects=>5, timeout=>10);
IF (aref (response, 0) NOT LIKE 'HTTP/% 20%') DB.DBA.OAS_ERROR_HANDLER(response, result);
RETURN result;
};
Q: How do I use this plugin in situations where I don’t want to share private data with a 3rd party hosted service?
A: Use the private edition of ChatGPT available via Microsoft Azure, and the simply leverage SPARQL Plugin portability.
Q: Okay, even within the context of a Microsoft Azure based private instance of ChatGPT and the SPARQL Plugin, how do I control access to SPARQL-accessible data?
A: If the SPARQL endpoint is Virtuoso-based, simply leverage the sophisticated attribute-based access controls (ABAC) provided by its Virtual Authentication & Authorization Layer (VAL).