Background
For a while, we’ve been able to embed SPARQL queries in HTML documents and have the OSDI (OpenLink Structured Data Inclusion-engine) evaluate them in-line, as part of rendering the page; in the process, the OSDI also provides a few javascript functions to parse such resultsets into JSON structures, and automatically invokes jQuery-templates where a template and target are found.
We also know that upstream libraries can be included by simply linking to CDN repositories for JS and CSS; this has been used for various pivottable.js examples in the past.
The latest library of choice is DataFrames: this provides a tabular data-structure akin to R’s data.frame or Python’s pandas, complete with API for methods to access and filter by row or column. It even provides a way to query within the resultset using a SQL dialect, if required. DataFrames can be transformed between JSON representations: array (of arrays); array (of hashes); Collection.
Simple Example
This example shows how to include DataFrames in an OSDI SPA:
<html>
<head>
<title>DataFrame Test</title>
<script src="https://gmousse.github.io/dataframe-js/dist/dataframe.min.js">
</script>
</head>
<body>
<script type="application/sparql-query" id="dftest">
prefix oplcorp:
<http://www.openlinksw.com/ontology/oplcorp#>
SELECT DISTINCT ?corp ?vp ?vpclaim ?vpdesc (STR(?vpdepiction) AS ?vpdepiction) ?rank
FROM <urn:webdev:virtuoso> { ?corp oplcorp:hasValueProposition ?vp . ?vp schema:name ?vpclaim ; schema:description ?vpdesc ; schema:image ?vpdepiction ; oplcorp:hasRank ?rank . } ORDER BY ?rank
</script>
<div class="container" style="margin-top: 5em">
<div class="row">
<p>This bit comes from a DataFrame</p>
<div id="dftesttarget">
</div>
</div>
</div>
<script type="text/javascript">
function mkdf() {
var DataFrame = dfjs.DataFrame;
var data = embedToData("dftest")
var df = new DataFrame(data)
return df
}
var df = mkdf()
$("#dftesttarget").html("<pre>" + df.select("rank", "vpclaim").show() + "</pre>");
$("#dftest").toggle(false)
</script>
</body>
</html>

(By default, df.show() truncates all columns to 10 characters wide.)
Tour de Force
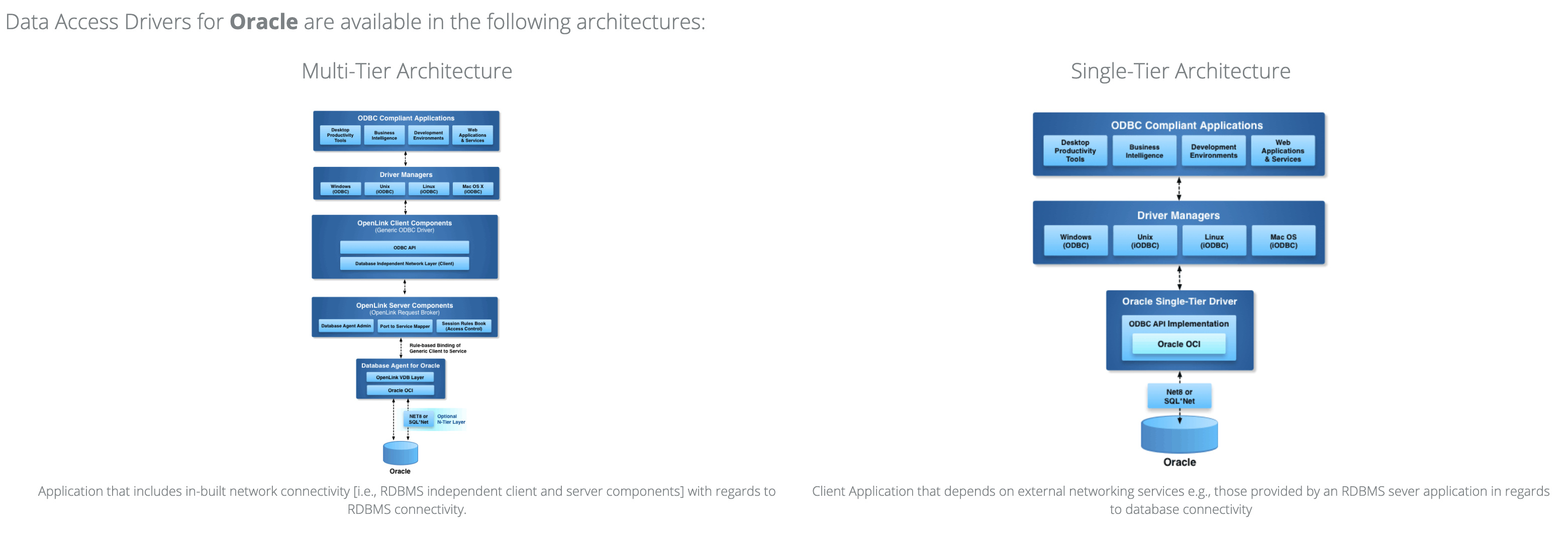
Perhaps the most complex example of an Single-Page Application (SPA) developed using the OSDI module is the drivers.vsp associated with the OpenLink Data Access Drivers for ODBC, JDBC, ADO.NET Web Site, where one script powers all the entries in the Databases menu, i.e., information about our data-access drivers / connectors for Oracle, Sybase, PostgreSQL, etc.
Structural Analysis
The pages powered by drivers.vsp consist of three segments:
- a top section detailing OpenLink UDA’s support for RDBMS-specific features
- a middle section showing the architectures/formats in which the drivers are available (Single-Tier Lite Edition and/or Multi-Tier Enterprise Edition)
- a lower section listing the features of Single-Tier (ST) and Multi-Tier (MT) architectures
Virtuoso Server Page (VSP) Example
As its name suggests, drivers.vsp is a VSP script — for the sole purpose of being able to parameterize the RDBMS in the queries involved.
First Query
The first query, for RDBMS-specific features, is a simple case of embedded SPARQL to jQuery-templates:
<script type="application/sparql-query" id="featbenprod" data-oplembed-template="featbenprod-template" data-oplembed-target="featbenprod-target">
PREFIX oplfeat: <http://www.openlinksw.com/ontology/features#>
PREFIX oplprod: <http://www.openlinksw.com/ontology/products#>
PREFIX oplben: <http://www.openlinksw.com/ontology/benefits#>
PREFIX schema: <http://schema.org/>
PREFIX opllic: <http://www.openlinksw.com/ontology/licenses#>
PREFIX oplsoft: <http://www.openlinksw.com/ontology/software#>
SELECT DISTINCT
(?feature AS ?featureID) ?feature (STR(?featureName) AS ?featureLabel)
(STR(?featureSynopsis) AS ?featureSynopsis) (bif:md5(?featureID) AS ?hash)
?benefitID (STR(?benefitLabel) AS ?benefitLabel)
(STR(?benefitSynopsis) AS ?benefitSynopsis)
{
GRAPH <urn:webdev:uda> {
?prod oplfeat:hasFeature ?feature .
?prod oplsoft:hasDatabaseEngine ?dbEngine .
?dbEngine schema:name ?dbEngineName .
FILTER(bif:contains(?dbEngineName, '"<?=rdbms?>"'))
?feature schema:name ?featureName; schema:description ?featureSynopsis ; oplben:hasBenefit ?benefitID .
?benefitID a oplben:Benefit; schema:name ?benefitLabel ; schema:description ?benefitSynopsis .
}
}
ORDER BY ?format ?prod ?feature ?benefit
LIMIT 250
</script>
Second Query
The second query, for determining the available formats, is much the same — embedded SPARQL to jQuery-templates.
Third Query
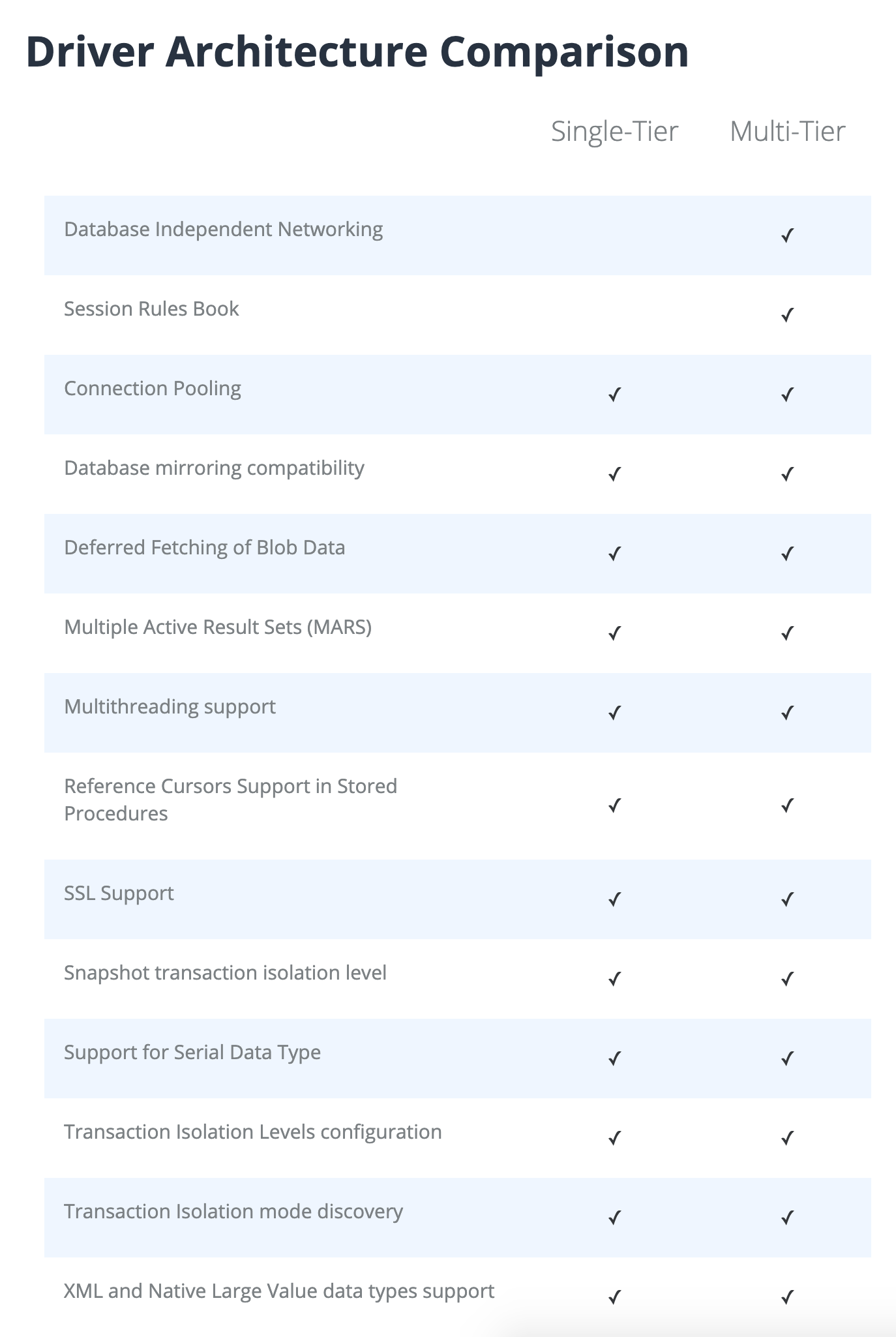
The third query, for building the feature-comparison matrix, is more complicated.
The SPARQL evaluated is:
<script type="application/sparql-query" id="udaformatfeatures">
PREFIX oplfeat: <http://www.openlinksw.com/ontology/features#>
PREFIX oplprod: <http://www.openlinksw.com/ontology/products#>
PREFIX oplben: <http://www.openlinksw.com/ontology/benefits#>
PREFIX schema: <http://schema.org/>
PREFIX opllic: <http://www.openlinksw.com/ontology/licenses#>
PREFIX oplsoft: <http://www.openlinksw.com/ontology/software#>
SELECT DISTINCT ?format (?feature AS ?featureID) (STR(?featureName) AS ?featureLabel)
(STR(?featureSynopsis) AS ?featureSynopsis) ?benefitID (STR(?benefitLabel) AS ?benefitLabel)
(STR(?benefitSynopsis) AS ?benefitSynopsis) (STR(?formatImage) AS ?formatImage)
(STR(?formatName) AS ?formatName) (STR(?prodImage) AS ?prodImage)
FROM <urn:webdev:uda> {
?prod oplprod:hasFormat ?format .
?prod oplsoft:hasDatabaseEngine ?dbEngine ; schema:image ?prodImage .
?format oplfeat:hasFeature ?feature .
?dbEngine schema:name ?dbEngineName .
FILTER(bif:contains(?dbEngineName, '"<?=rdbms?>"'))
?format a oplprod:ProductFormat ; schema:name ?formatName ; schema:image ?formatImage .
?feature schema:name ?featureName; schema:description ?featureSynopsis ; oplben:hasBenefit ?benefitID .
?benefitID a oplben:Benefit; schema:name ?benefitLabel ; schema:description ?benefitSynopsis .
FILTER(?format != <http://data.openlinksw.com/oplweb/product_format/express#this> )
}
ORDER BY ?format ?feature ?benefitID
LIMIT 250
</script>
As can be seen, it filters to the current RDBMS in order to restrict the available products and thus the available features. (In other words: if we did not support Multi-Tier for a given RDBMS, it wouldn’t show up.)
DataFrame.JS
In order that the set of available formats and their images may be established, the resultset is processed in DataFrame-JS:
var df = mkdf("udaformatfeatures")
df=df.filter( row =>
(row.get("format").match(/\/mt#this/) && row.get("prodImage").match(/mt\./) ) ||
(row.get("format").match(/\/st#this/) && row.get("prodImage").match(/st\./)))
(Translation: rows are kept if and only if they contain mt in both the format and prodImage fields, or they contain st in both the format and prodImage fields; this eliminates cross-over cases from dirty data.)
This dataframe is used to populate the thumbnails in the preceding section concerning availability, in order that the images be specific to the RDBMS.
PivotTable
The last query is transformed using pivottable.js:
$("#udaformatfeaturescontainer").pivot(
data,
{
cols: ["format"],
rows: [ "featureID" ],
aggregatorName: "List Unique Values",
aggregator: mklicbox,
// aggregatorName: "Count",
rendererOptions: {table: {rowTotals: false, colTotals: false},
rowOrder: "value_z_to_a"
},
sorters: {
"format": $.pivotUtilities.sortAs(
["http://data.openlinksw.com/oplweb/product_format/st#this", "http://data.openlinksw.com/oplweb/product_format/mt#this"])
},
showUI: true
}
);
The order of format columns is chosen to be ST before MT. The aggregator is a custom function that simply returns the string "tick".
jQuery is used to —
- replace cells containing the string
"tick"with a unicode tick character - replace the column headings with the natural language labels — through a lookup against the dataframe to find the first formatName sharing the same URI as the column heading
- replace the row headings with the natural language labels — through another lookup against the dataframe to find the first featureName sharing the same URI as the row heading
- add misc CSS transformations, e.g., for column width
- implement a sort by the ST column in order that unticked cells migrate to the top, exposing the differences between ST and MT more clearly.
Lightbox
One last thing: the ekko lightbox library is used for all image thumbnails, to provide a pleasant lightbox expansion on click.