Let’s Talk About RAG
Why RAG is Needed
Large Language Models (LLMs) are incredibly powerful at generating fluent text. However, they are inherently probabilistic and can produce outputs that are factually incorrect—often referred to as “hallucinations.” This is particularly problematic in enterprise or high-stakes environments, where factual accuracy is critical.
Retrieval-Augmented Generation (RAG) addresses this challenge by combining generative language capabilities with explicit retrieval from external, authoritative data sources. By grounding LLM outputs in real-world data, RAG mitigates hallucinations and increases trustworthiness.
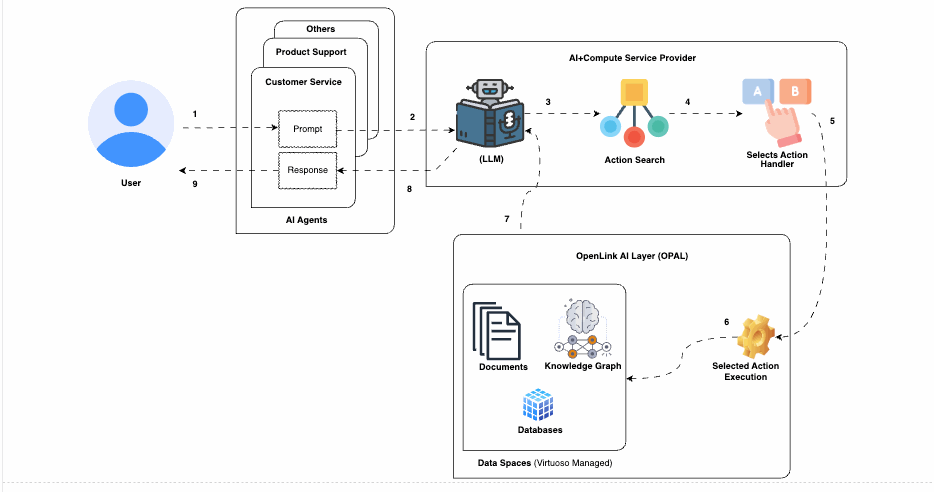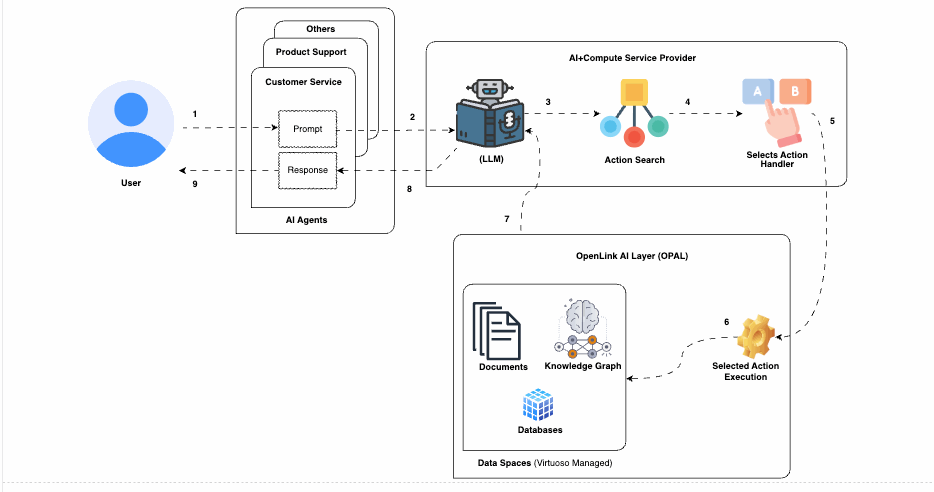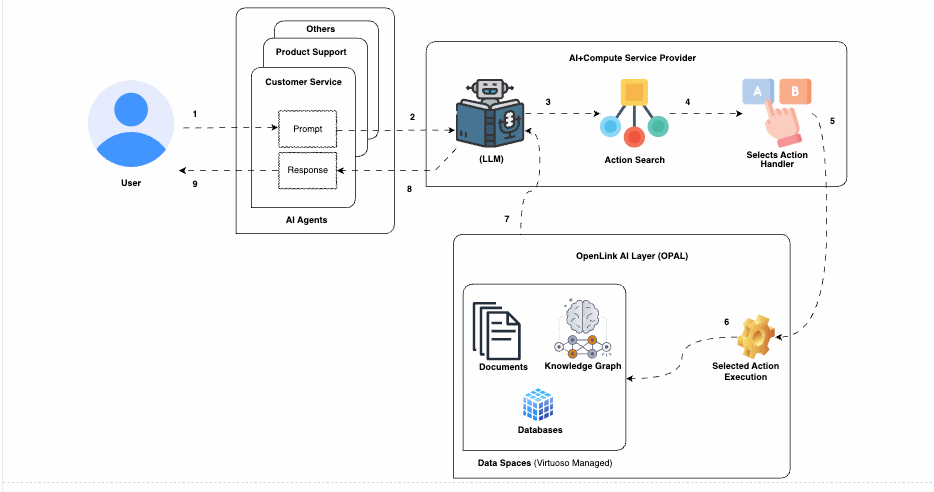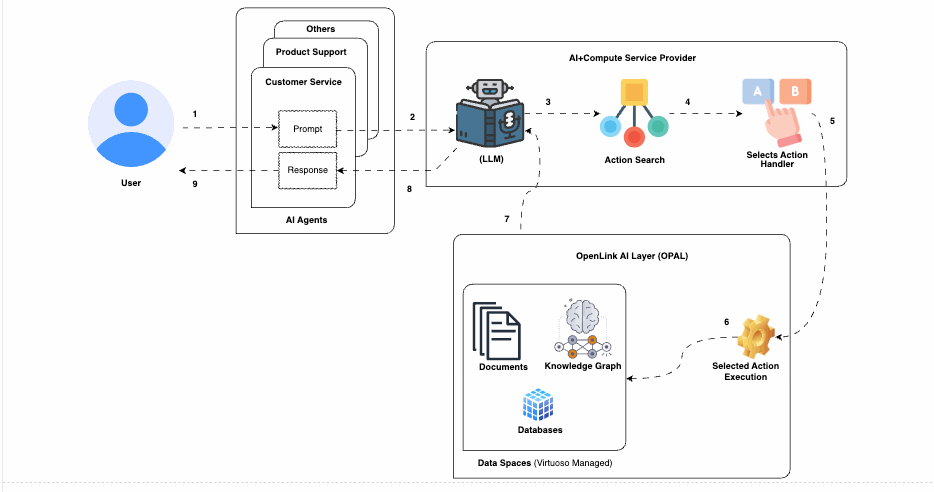
How RAG Works
RAG mechanisms provide context to the LLM by retrieving relevant information from structured or unstructured sources before or during generation. Depending on the approach, this can involve:
- Vector-based retrieval: Using semantic embeddings to find the most relevant content.
- Graph-based queries: Traversing relationships in labeled property graphs or RDF knowledge graphs.
- Neuro-Symbolic combinations: Integrating vector retrieval with RDF-based knowledge graphs via SPARQL or SQL queries to balance semantic breadth and factual grounding.
The LLM consumes the retrieved content as context, producing outputs that are both fluent and factually reliable.
What RAG Delivers
When implemented effectively, RAG empowers AI systems to:
- Provide factually accurate answers and summaries.
- Combine unstructured and structured data seamlessly.
- Maintain provenance and traceability of retrieved information.
- Reduce hallucinations without sacrificing the generative flexibility of LLMs.
1. Vector Indexing RAG
Summary:
Pure vector-based RAG leverages semantic embeddings to retrieve content most relevant to the input prompt. This approach is fast and semantically rich but is not inherently grounded in formal knowledge sources.
Key Points:
- Uses embeddings to find top-K semantically similar content.
- Works well with unstructured text (documents, PDFs, notes).
- Quick retrieval with high recall for semantically relevant items.
Pros:
- Very flexible; can handle unstructured or loosely structured data.
- Fast retrieval due to vector similarity calculations.
- Easy to implement with modern vector databases.
Cons:
- Lacks formal grounding in structured knowledge.
- High risk of hallucinations in LLM outputs.
- No native support for reasoning or inference.
- Requires content reindexing for initial construction and change-sensitivity.
2. Graph RAG (Labeled Property Graphs)
Summary:
Graph RAG uses labeled property graphs (LPGs) as the context source. Queries traverse nodes and edges to surface relevant information.
Key Points:
- Supports domain-specific analytics over graph relationships.
- Node/edge metadata enhances context precision.
- Useful for highly interconnected datasets.
Pros:
- Enables graph traversal and relationship-aware retrieval.
- Effective for visualizing connections in knowledge networks.
- Allows fine-grained context selection using graph queries.
Cons:
- Proprietary or non-standardized; limited interoperability.
- Does not inherently support global identifiers like RDF IRIs.
- Semantics are implicit and application-specific.
- Scaling across multiple systems or silos can be challenging.
3. RDF-based Knowledge Graph RAG
Summary:
Uses RDF-based knowledge graphs with SPARQL or SQL queries, informed by ontologies, as the context provider. Fully standards-based, leveraging IRIs/URIs for unique global identifiers.
Key Points:
- Traverses multiple silos using hyperlink-based identifiers or federated SPARQL endpoints.
- Supports semantic reasoning and inference informed by ontologies.
- Provides provenance for retrieved context.
Pros:
- Standards-based, interoperable, and transparent.
- Strong grounding reduces hallucination risk.
- Can leverage shared ontologies for reasoning, inference, and schema constraints.
Cons:
- Requires structured RDF data, which can be resource-intensive to maintain.
- Historically unfamiliar due to the lack of a natural client complement until the arrival of LLMs.
4. Neuro-Symbolic RAG (Vectors + RDF + SPARQL)
Summary:
Combines the semantic breadth of vector retrieval with the factual grounding of RDF-based knowledge graphs. This approach is optimal for RAG when hallucination mitigation is critical. OPAL-based AI Agents (or Assistants) implement this method effectively.
Key Points:
- Vector-based semantic similarity analysis discovers and extracts entities and entity relationships from prompts.
- Extracted entities and relationships are mapped to RDF entities/IRIs for grounding via shared ontologies.
- SPARQL or SQL queries expand and enrich context with facts, leveraging reasoning and inference within the solution production pipeline.
- The LLM is supplied with query solutions comprising a semantically enriched, factually grounded context for prompt processing.
- Significantly reduces hallucinations while preserving fluency.
Why It Works:
- Harnesses semantic vector search to quickly narrow down candidate information.
- Grounding via RDF and SPARQL (or SQL) ensures retrieved information is factual and verifiable.
- Seamlessly integrates unstructured and structured data sources.
- Ideal for enterprise-grade AI Agents where precision, provenance, and context matter.
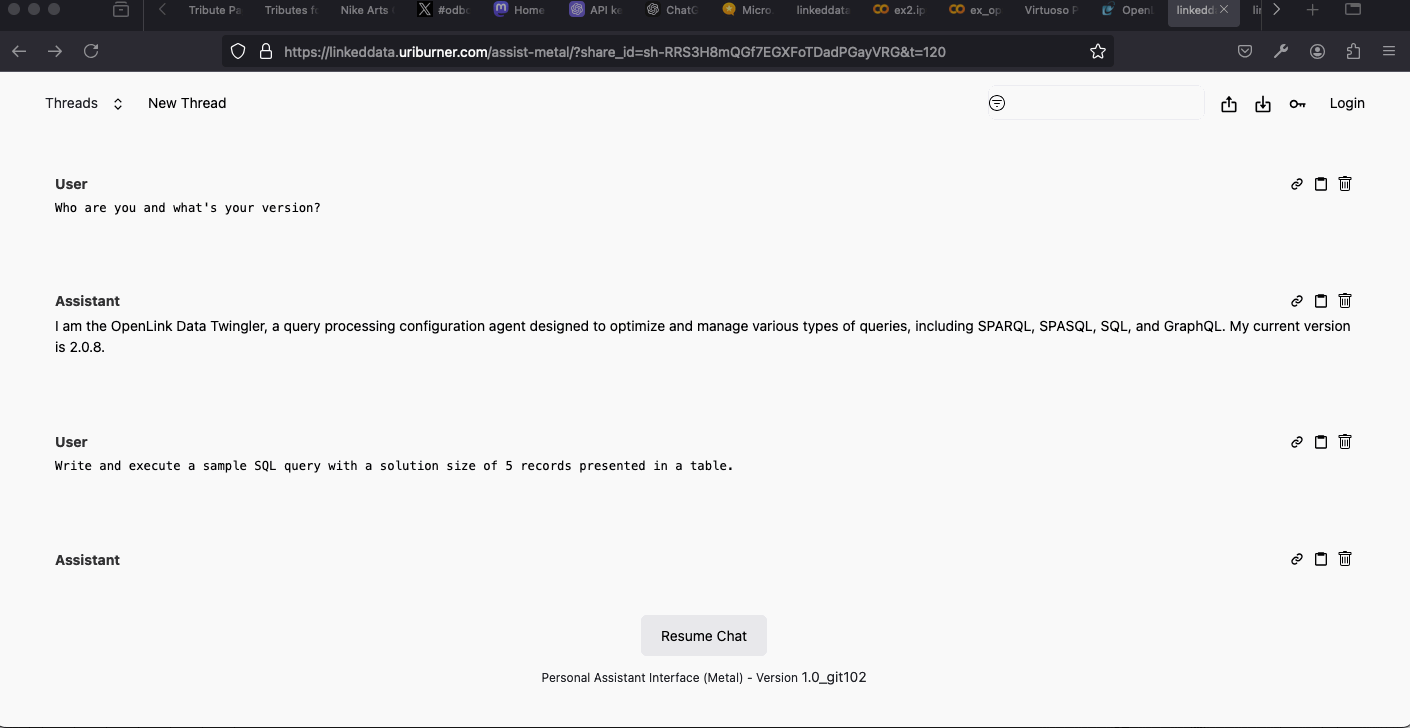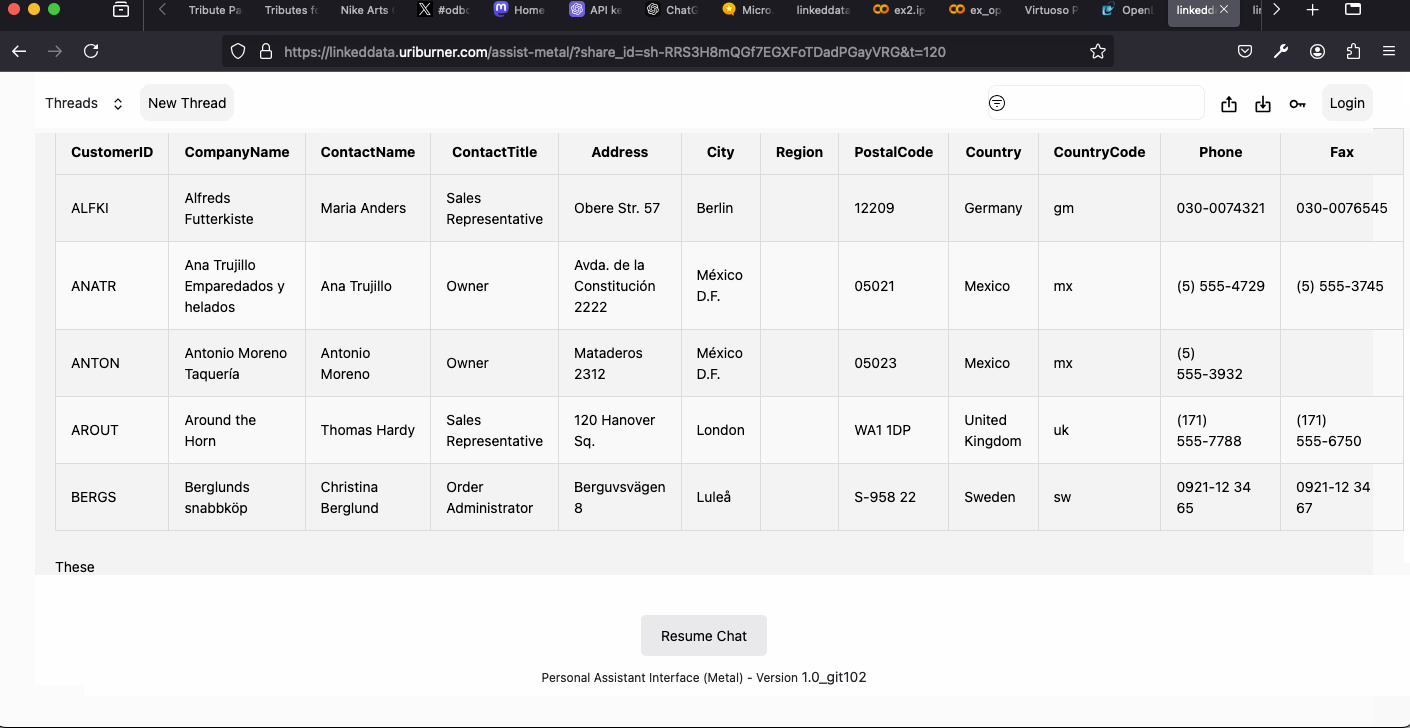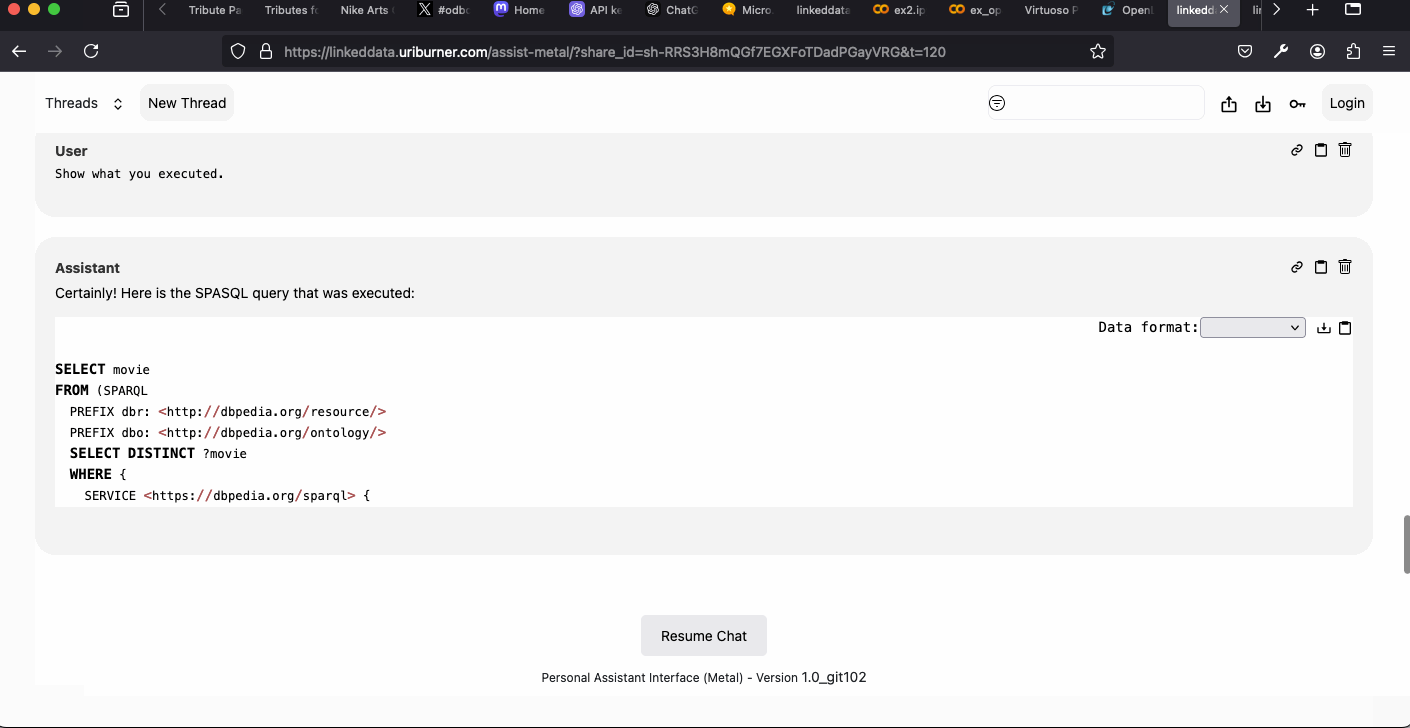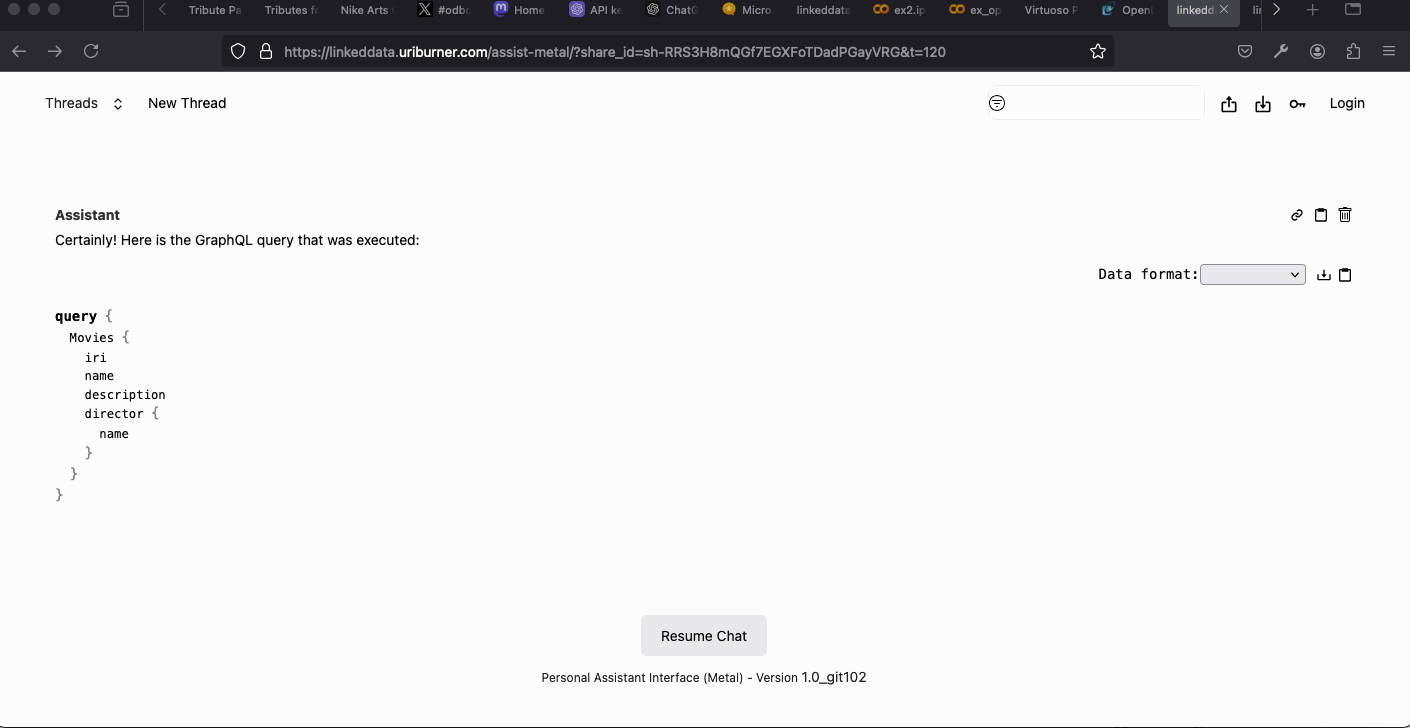
Examples – OPAL Assistant Neuro-Symbolic RAG:
- Data Twingler Query Agent – combines SQL, SPARQL, SPASQL, and GraphQL access for structured data retrieval.
- RSS Reader Agent – maps RSS/Atom feed items to a knowledge graph, combined with vector embeddings for semantic relevance.

- Virtuoso Support Agent – demonstrates fact-grounded Q&A over Virtuoso’s RDF and relational data using a Neuro-Symbolic RAG approach.
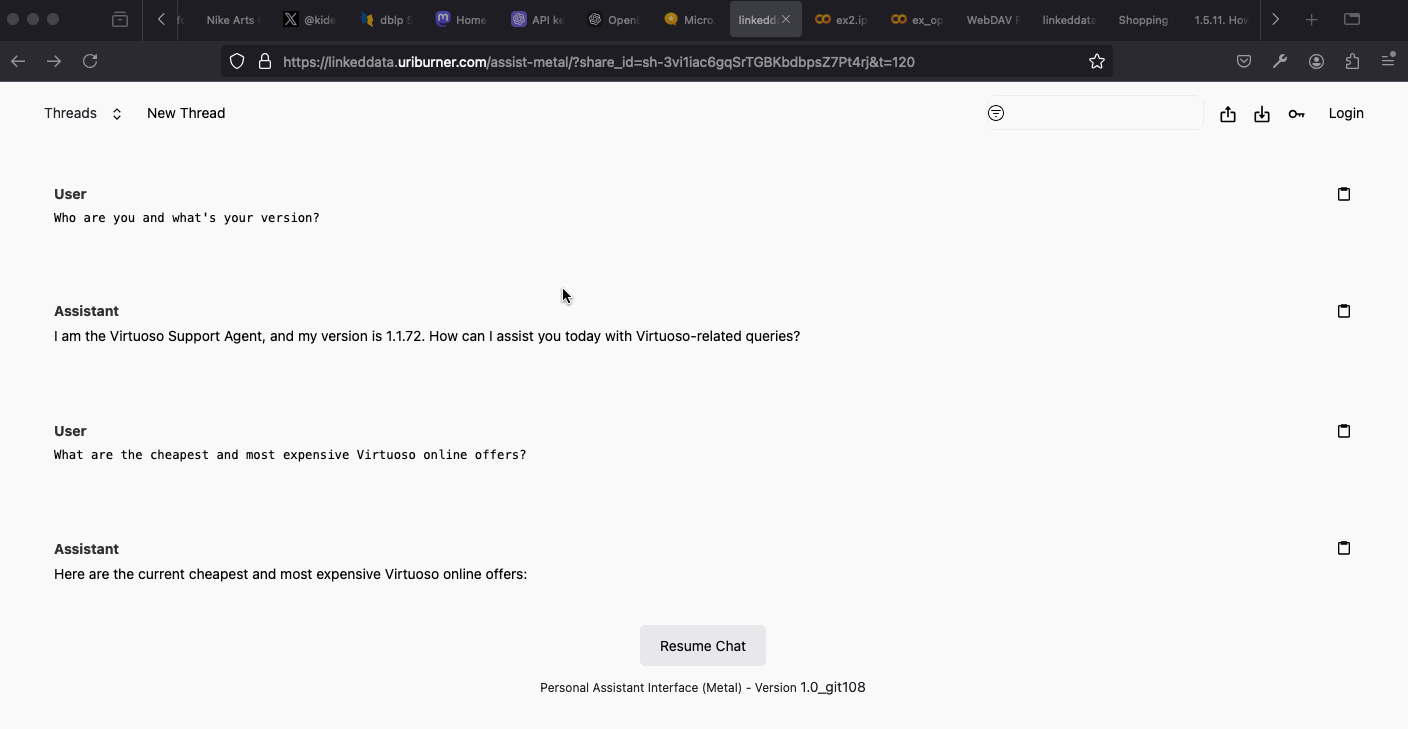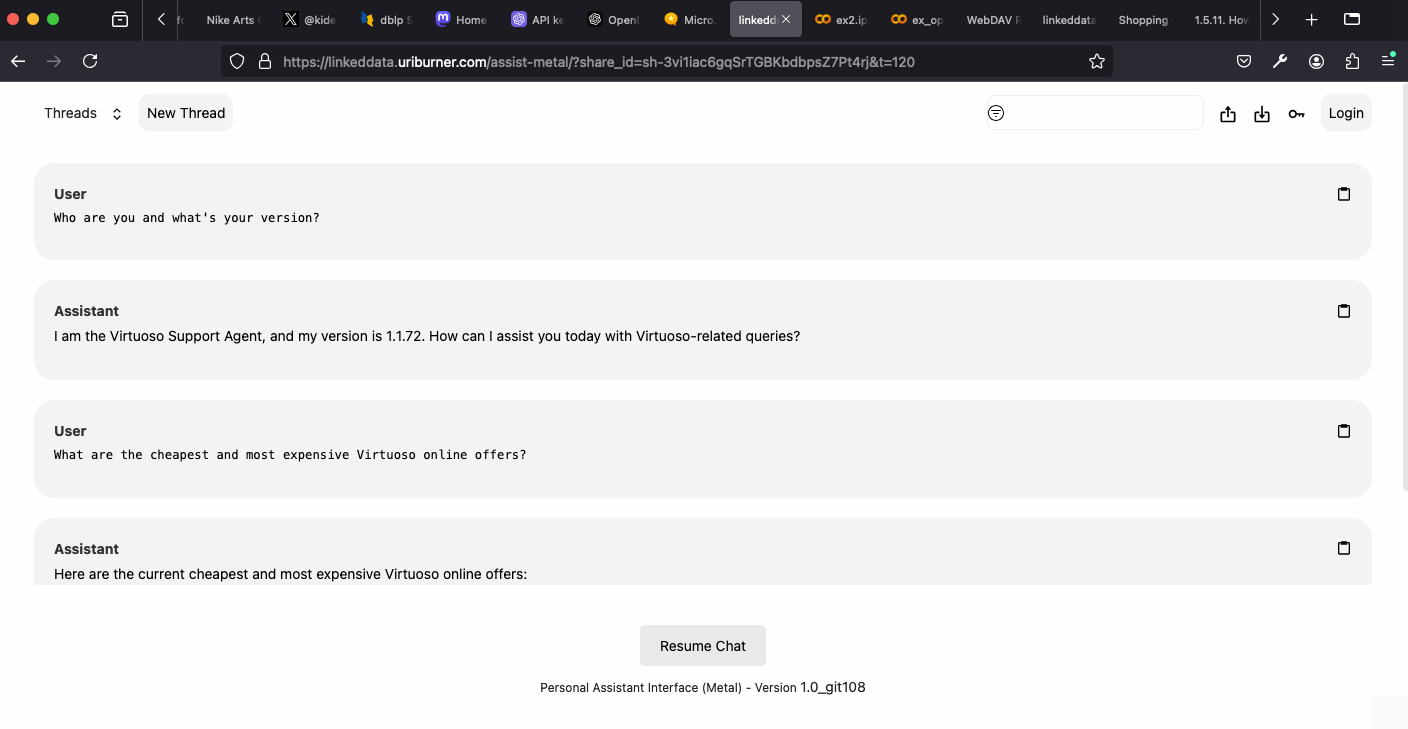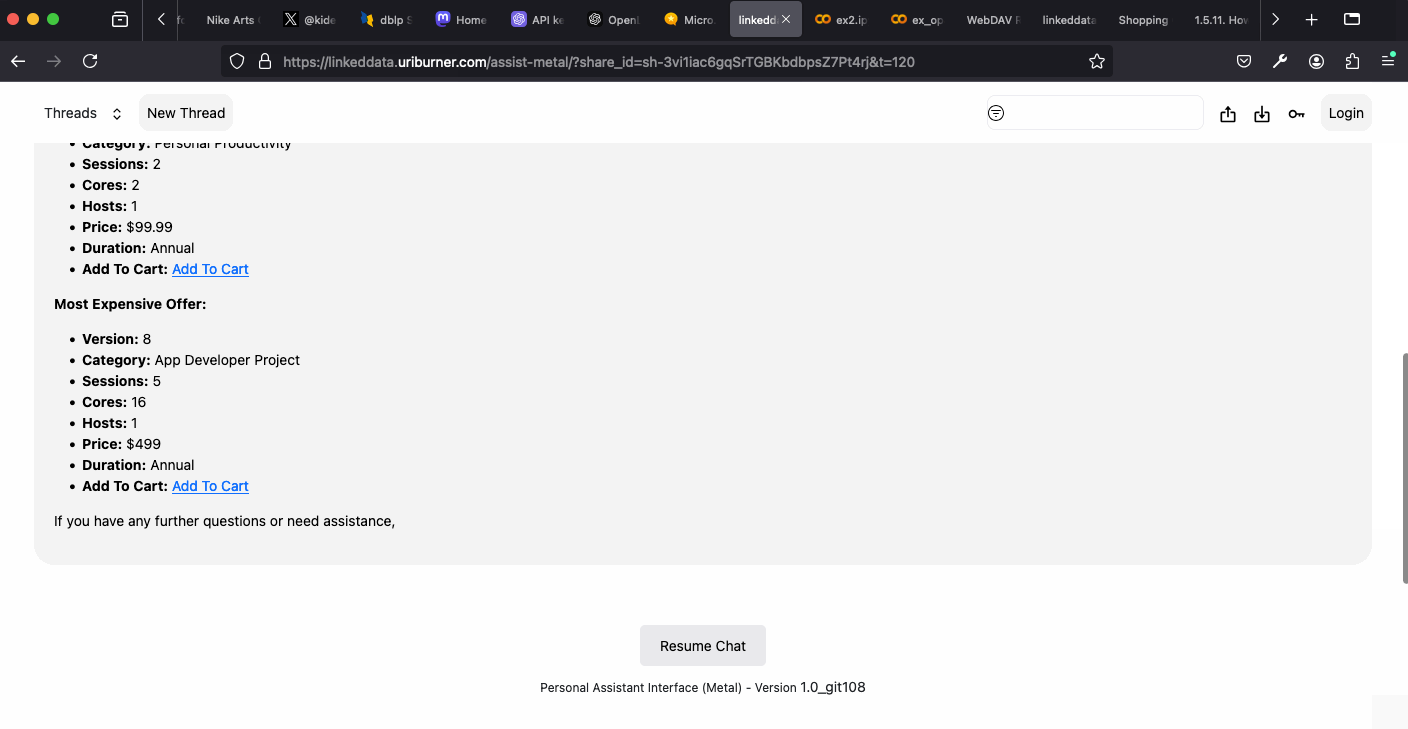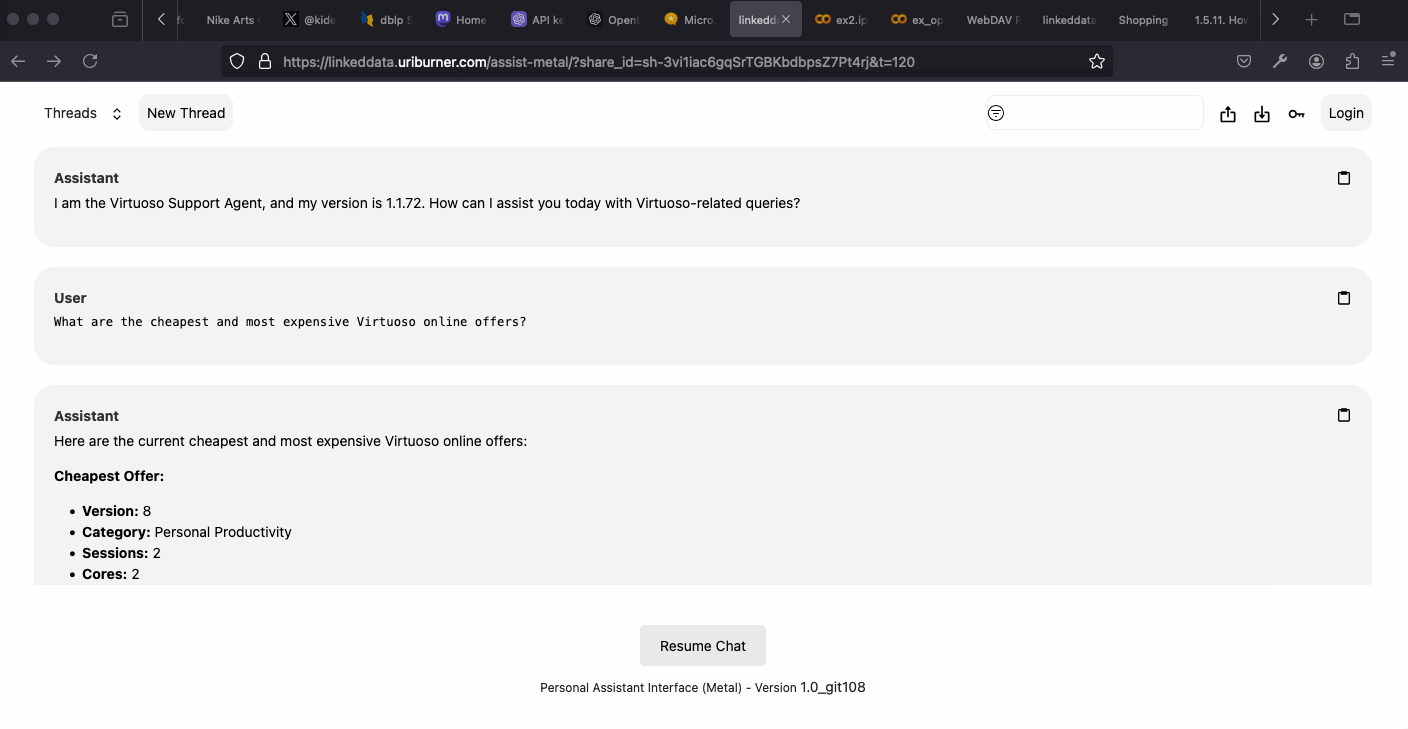
Conclusion
While each RAG approach has strengths, combining vectors + RDF knowledge graphs + SPARQL offers the optimal balance of speed, semantic relevance, and factual grounding. Neuro-Symbolic RAG, as implemented in OPAL AI Agents, is a blueprint for robust, hallucination-resistant AI systems.
RAG Approach Comparison Table 1
| Approach | Key Feature | Pros | Cons | Best Use Case |
|---|---|---|---|---|
| Vector Indexing | Embeddings-based semantic retrieval | Flexible, fast, easy to implement | Lacks grounding, prone to hallucinations | Unstructured text, exploratory retrieval |
| Graph RAG (LPG) | Traversal of labeled property graphs | Graph-aware, fine-grained context | Non-standard, limited interoperability | Interconnected datasets, visualization |
| RDF-based KG RAG | SPARQL over RDF knowledge graphs | Standards-based, reasoning support, provenance | Slower retrieval, requires structured RDF | Fact-grounded enterprise Q&A |
| Neuro-Symbolic (Vectors + RDF + SPARQL) | Vector + RDF hybrid | Fast, factually grounded, reduces hallucinations | Requires both structured RDF and embeddings setup | Enterprise AI Agents, high-stakes decision support |
RAG Approach Comparison Table 2
| Approach | Pros | Cons | Use Case Fit |
|---|---|---|---|
| Vector Indexing | Fast, scalable; Semantic similarity; Easy integration | Lacks relational context; Hard to trace | Similarity-based search |
| LPG Graph RAG | Captures relationships; Structured traversal; Some reasoning | Siloed; Limited reach; Complex | Entity relationship exploration |
| RDF Knowledge Graph | Standards-based; Provenance; Reasoning | Ontology-dependent; Slow; Complex | Factual, cross-domain retrieval |
| Neuro-Symbolic | Combines reach + precision; Reasoning; Traceability | More complex | High-stakes accuracy |