Here’s a simple How-To style guide for uploading the “CrunchBase RDF Data Set” from the Zenodo RDF Dataset Repository into a Virtuoso instance.
I will be using our URIBurner Service as the Virtuoso instance example in this guide.
Steps:
-
Download the dump file (
crunchbase-dump-2015-10.nt.gz) to the URIBurner Virtuoso host, and put it in a directory (/opt/ubv7n/dumps/) which is included in the URIBurner instance’s INI file (in theDirsAllowedparameter value). -
Load the data into a Virtuoso instance using the following SQL command sequence:
ld_dir ('/opt/ubv7n/dumps/', 'crunchbase-dump-2015-10.nt.gz', 'https://zenodo.org/record/3270905/files/crunchbase-dump-2015-10.nt.gz') ; SELECT * FROM DB.DBA.load_list WHERE ll_state = 0 ; rdf_loader_run(); -
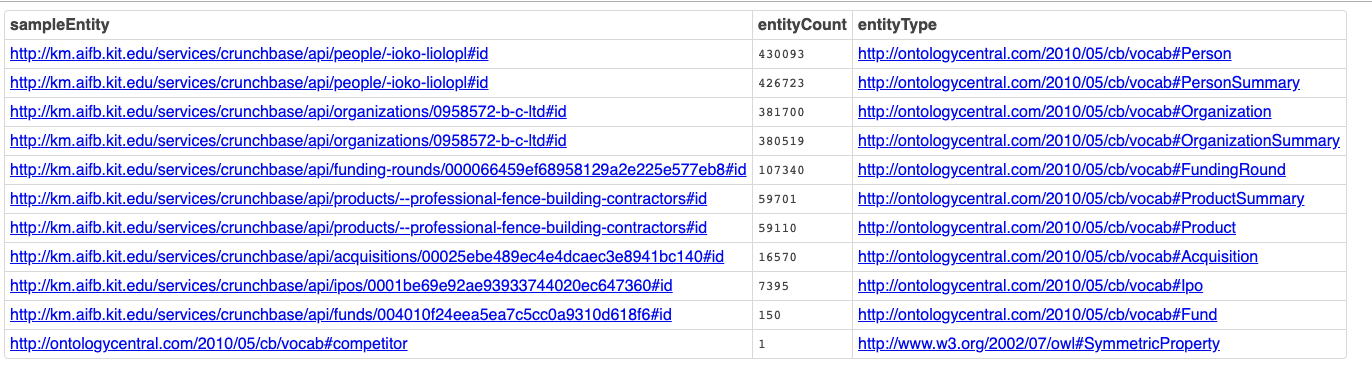
Verify the effects of the load commands with the following SPARQL query:
SELECT DISTINCT ( SAMPLE(?s) AS ?sampleEntity ) ( COUNT(1) AS ?entityCount ) ( ?o AS ?entityType ) FROM <https://zenodo.org/record/3270905/files/crunchbase-dump-2015-10.nt.gz> WHERE { ?s a ?o . FILTER ( isIRI(?s) ) } GROUP BY ?o ORDER BY DESC 2 -
Here’s a screenshot of the query results. Each link resolves to a Faceted Browsing Page that provides deeper exploration of the Entity Relationships and Entity Relationship Types that underly this Knowledge Graph.