Every Web Browser includes a bookmark manager and associated features that provide a user with the ability to save links to Web Pages they’ve visited for future recall. Unfortunately, as currently delivered, this functionality doesn’t scale and as a result is decreasingly used — net effect, a lessening ability to recall and share interesting documents (e.g., blog posts, newspaper articles, etc.).
In response to the this frailty, a number of bookmarking services emerged during the Web 2.0 era, of which del.icio.uswas dominant. Sadly, this service no longer exists, and in many cases the bookmark collections stored there are no longer available to their original creators.
What’s the problem here?
Bookmarking apps and services boil down to providing users with a few input/capture fields for describing a bookmarked document:
- Network Location — delivered via a hyperlink (typically, a HTTP URL)
- Title
- Description
- Associated Tags
The problem is that the entity relationship graph (an index of documents) created by the user’s act of bookmarking is controlled by and ultimately serves the needs of the service provider rather than those of the end-user, who simply — and desperately — wants to be able to recall and share these links at will.
What’s a practical solution?
Use the existing interaction pattern — i.e., when viewing a page of interest, simply click to bookmark — to deliver a solution that serves the needs of both the end-user and service provider.
How does the solution work?
Our URIBurner Service (or your own Virtuoso Instance, with the Sponger Middleware module enabled) has a built-in ability to bookmark any Web Page with a single click (if our OpenLink Data Explorer [ODE] Extensionis installed and active in your Browser) or with a simple URL pattern that you can apply to your Browser’s Address Bar (potentially with a browser-local bookmarklet ) the moment you decide a document is worth bookmarking.
Simple live example?
Schema.orgis an interesting project that seeks to build a very high-level vocabulary (or ontology) of terms (with an English orientation) covering many aspects of what’s referred to as general human knowledge. Like many projects these days, it is hosted by GitHubwhich provides a space for Issue Management amongst other goodies.
Here are the simple actions you can perform to bookmark every single issue associated with the Schema.org project. Either:
- load the project’s issues page — GitHub · Where software is built — in your browser, and click the ODE icon in your browser’s Extension Toolbar
- load a URIBurner page, using the URL Pattern for Rich Bookmarking — https://linkeddata.uriburner.com/about/html/https/github.com/schemaorg/schemaorg/issues.
Irrespective of which of these actions you choose, the following page will be returned to your Browser:
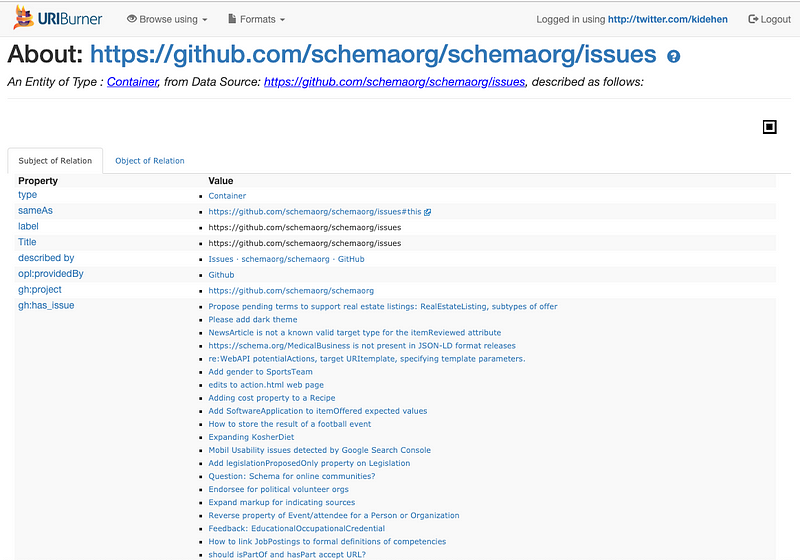
URIBurner Bookmark Response Page
The page above indicates completion of the following actions:
- Generation of a description of all the issues on Github associated with the Schema.org project
- Storage of the collection of issue descriptions in the Virtuoso DBMS that underlies the URIBurner Service instance — including indexing the text associated with each issue description
You can scope the bookmarking action to a specific issue by starting with the specific URL of that issue instead of the issue management index — i.e., GitHub · Where software is built of GitHub · Where software is built.
Benefits?
You have now created an issues-oriented Knowledge Graph that manifests as a Semantic Web; i.e., every entity is unambiguously identified by a hyperlink, and is described using a subject→predicate→object structured sentence — where the subject and predicate, and optionally the object, are also unambiguously identified by a hyperlink (specifically, an HTTP URI). Thus, you can recall a specific bookmark through a Keyword Search, using Precision Find or a SPARQL Query.
Keyword Search using Precision Find
Search by Phrase Example
Go to http://linkeddata.uriburner.com/fctand type in the following, verbatim (including the wrapping quotes): "Real Estate"
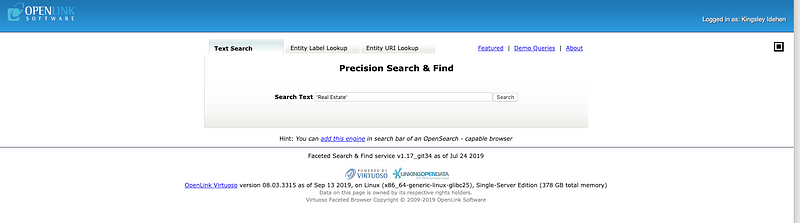
Click on the Search button, and you’ll be presented with a page containing a list of properties that have literal values associated with the phrase Real Estate . (If you left out the quotation marks, the literal values will contain both Real and Estate , but they may not form a phrase.) Using CTRL+F (shortcut for Find , i.e., text search on page content), you can quickly locate gh:has_issue in the list:

Live Page [ Link ]
Click on that property label, and you will be presented with the screen depicted below.
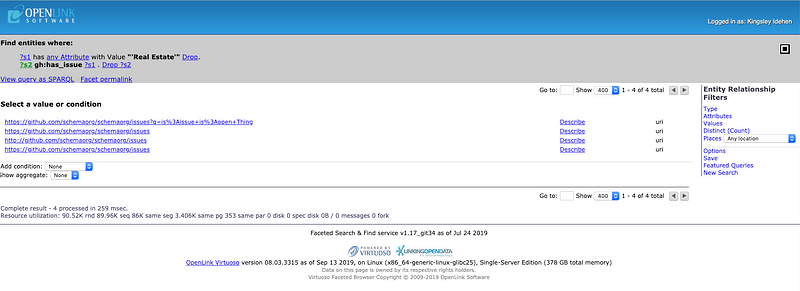
Live Page [ Link ]
Move the page focus from ?s2 (variable that denotes all entity types that have a property labeled gh:has_issue ) back to ?s1 (variable that denotes all issues that are values of the gh:has_issue property) — again, by clicking on ?s1 , this time in the gray bar — which results in the page depicted blow.
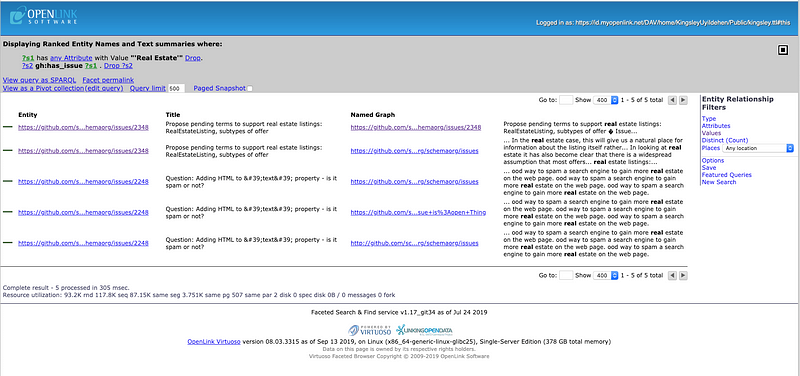
Live Page [ Link ]
Select a specific issue by clicking on the value presented in the entity column, which will present a page like that depicted below, i.e., a detailed description (in property-sheet style) of the selected entity.
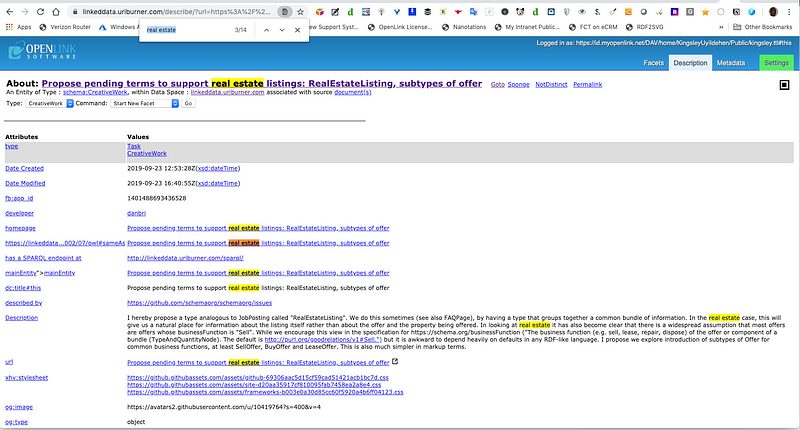
Live Page [ Link ]
Basic SPARQL Query Example
PREFIX gh: <http://www.openlinksw.com/schemas/github#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?o AS ?issueID xsd:string(?title) AS ?issueTitle
FROM <https://github.com/schemaorg/schemaorg/issues>
WHERE {
?s gh:has_issue ?o.
?o dc:title ?title .
}
Query Results

Live Query Results [ Link ]
SPARQL Query Example that includes Keyword Search
PREFIX gh: <http://www.openlinksw.com/schemas/github#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?o AS ?issueID
xsd:string(?description) AS ?synopsis
FROM <https://github.com/schemaorg/schemaorg/issues>
WHERE {
?s gh:has_issue ?o.
?o dc:title ?title .
FILTER (bif:contains(?description,"'Real Estate'"))
FILTER (?o = <https://github.com/schemaorg/schemaorg/issues/2348>)
}
Query Results

Live Query Results [ Link ]
Conclusion
Bookmarks don’t need to be a dying aspect of the Web experience. As demonstrated in this post, the same old bookmarking pattern for content sharing and recall is reusable in a much richer interaction pattern that also revitalizes knowledge-sharing via Knowledge Graphs that manifest as a Semantic Web comprising Linked Data.
Bookmarking can evolve into a fun act that broadens knowledge and revitalizes old disciplines in the process!