Using Twitter as my source of data to construct a Social Network, here are SPARQL examples using common Network (Graph) Analytics algorithms.
Centrality
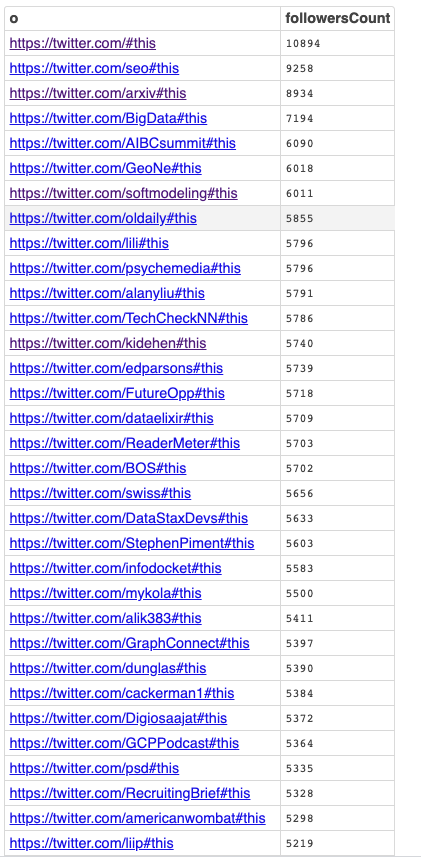
SELECT ?o
( COUNT(*) AS ?followersCount )
FROM <urn:tweets:kg>
FROM <urn:twitter:analytics:all>
WHERE { ?s opltw:follows ?o }
GROUP BY ?o
ORDER BY DESC ( ?followersCount )
LIMIT 100
Live Query [LINK]
Degree Centrality
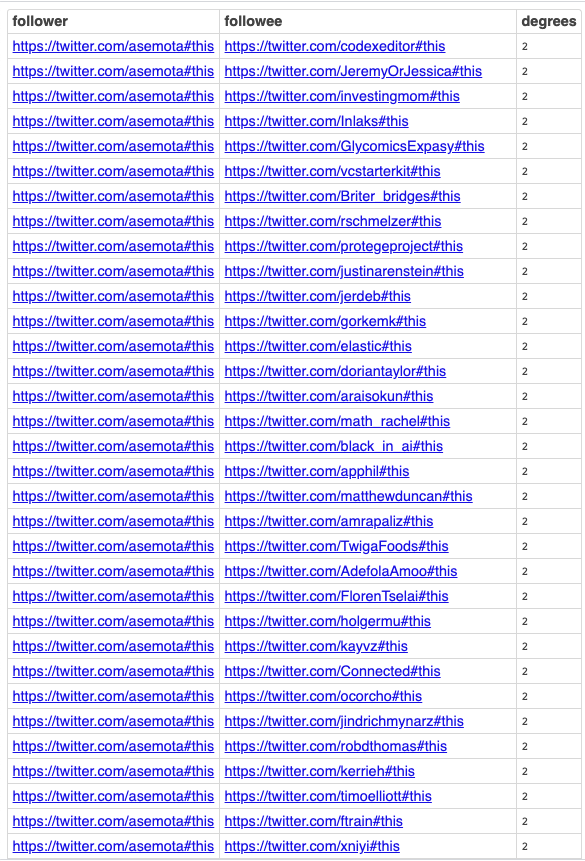
## follower (@asemeota) is 2-degrees of separation from the
## followees, i.e., he doesn't follow any of them directly
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?s as ?follower
?o as ?followee
( SUM ( ?dist ) AS ?degrees )
FROM <urn:twitter:analytics:all>
WHERE
{
?s opltw:follows ?o
OPTION (
TRANSITIVE ,
T_DISTINCT ,
T_SHORTEST_ONLY ,
T_IN ( ?s ) ,
T_OUT ( ?o ) ,
T_MIN ( 2 ) ,
T_STEP ( 'step_no' ) AS ?dist
)
FILTER ( ?s = <https://twitter.com/asemota#this> )
}
GROUP BY ?s ?o
Live Query [LINK]
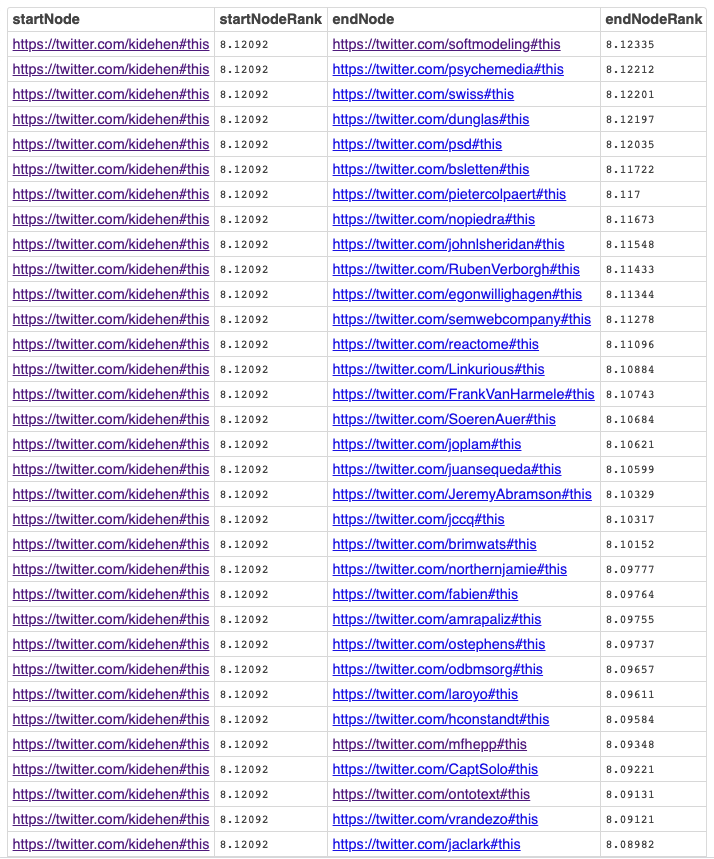
Precomputed S-Rank (a variant of Eigen Vector Centrality)
PREFIX custom-rank: <LONG::>
SELECT ?s AS ?startNode
sql:rnk_scale ( SUM ( custom-rank:IRI_RANK ( ?s ) ) ) AS ?startNodeRank
?o AS ?endNode
sql:rnk_scale ( SUM ( custom-rank:IRI_RANK ( ?o ) ) ) AS ?endNodeRank
FROM <urn:twitter:analytics:all>
# FROM <urn:tweets:kg>
WHERE
{
?s opltw:follows ?o
FILTER ( ?s = <https://twitter.com/kidehen#this> )
}
GROUP BY ?s ?o
ORDER BY DESC ( ?startNodeRank ) DESC ( ?endNodeRank )
LIMIT 100
Live [LINK]